 用户中心
用户中心通过robots协议屏蔽搜索引擎抓取网站内容
有时候有些页面访问消耗性能比较高不想让搜索引擎抓取,可以在根目录下放robots.txt文件屏蔽搜索引擎或者设置搜索引擎可以抓取文件范围以及规则。
Robots协议 (也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。

Robots协议写法说明
User-agent: 这里的 代表的所有的搜索引擎种类,*是一个通配符;
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录;
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录;
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录;
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以”.htm”为后缀的URL(包含子目录);
Disallow: /禁止访问网站中所有包含问号 (?) 的网址;
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片;
Disallow: /ab/adc.html 禁止爬取ab文件夹下面的adc.html文件;
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录;
Allow: /tmp 这里定义是允许爬寻tmp的整个目录;
Allow: .htm$ 仅允许访问以”.htm”为后缀的URL;
Allow: .gif$ 允许抓取网页和gif格式图片;
Sitemap: 网站地图地址 告诉爬虫这个页面是网站地图;
Robots协议举例
例1. 禁止所有搜索引擎访问网站的任何部分:
User-agent: * Disallow: /
例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt”):
User-agent: * Allow: /
例3. 禁止某个搜索引擎的访问:
User-agent: BadBot Disallow: /
例4. 允许某个搜索引擎的访问:
User-agent: Baiduspider Allow:/
更多写法请参考:
robots文件介绍、作用及写法
在接手一个网站时,无论做什么诊断分析,都少不了检查robots文件,为什么有的网站天天发文章却未见收录,很有可能是因为被robots文件里的规则屏蔽搜索引擎抓取所导致的。那么什么是robots文件,对于一个网站它的作用的什么?本文白天为你详细介绍robots文件并教你robots文件正确的写法。 一、robots文件简介 简单来说就是一个以robots命名的...
 robots文件
sitemap文件
robots文件
sitemap文件
原创文章,作者:白天,如若转载请注明出处: 通过robots协议屏蔽搜索引擎抓取网站内容
如何屏蔽蜘蛛抓取
如何禁止搜索引擎爬虫抓取网站页面
下面是一些阻止主流搜索引擎爬虫(蜘蛛)抓取/索引/收录网页的思路。注:全网站屏蔽,尽可能屏蔽主流搜索引擎的所有爬虫(蜘蛛)。1.被文件阻止
可以说文件是最重要的渠道(可以和搜索引擎建立直接对话),给出以下建议:
用户代理:Baiduspider
不允许:/
用户代理:Googlebot
不允许:/
用户代理:谷歌机器人手机
不允许:/
用户代理:谷歌机器人图像
不允许:/
用户代理:Mediapartners-Google
不允许:/
用户代理:Adsbot-Google
不允许:/
用户代理:Feedfetcher-Google
不允许:/
用户代理:雅虎!大声地吃
不允许:/
用户代理:雅虎!啜饮中国
不允许:/
用户代理:雅虎!-广告爬虫
不允许:/
用户代理:有道机器人
不允许:/
用户代理:Sosospider
不允许:/
用户代理:网络蜘蛛
不允许:/
用户代理:网络网络蜘蛛
不允许:/
用户代理:MSNBot
不允许:/
用户代理:ia_archiver
不允许:/
用户代理:番茄机器人
不允许:/
用户代理:*
不允许:/
2.按元标签屏蔽
将以下语句添加到所有网页头文件中:
3.通过服务器的配置文件来设置(比如Linux/nginx)
直接过滤蜘蛛/机器人的IP段。
SEO优化图片有哪些方法?
图片优化要做上alt属性
图片大小要统一
图片的水印处理
要上传清晰的图片
没有必要优化你网站上的所有的图片。比如模板中使用的图片、导航中的图片还有背景图片等等,我们不用为这些图片添加ALT标签,我们可以把这些图片放在一个单独的文件夹里。并通过设置robots文件设置来阻止蜘蛛抓取这些图片。
如何不让google抓取我的网站
如果不希望 Google抓取网站内容,就需要在服务器的根目录中放入一个 文件,其内容如下:User-Agent: *Disallow: / 这是大部份网络漫游器都会遵守的标准协议,加入这些协议后,它们将不会再漫游您的网络服务器或目录。 Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
在线制作网站如何禁止蜘蛛收录网站在线制作网站如何禁止蜘蛛收录网站信息
我如何设置一个网站被禁止被爬虫收录?
网站建好之后,当然希望搜索引擎收录的页面越多越好,但是有时候我们也会遇到网站不需要被搜索引擎收录的情况。比如启用一个新域名作为镜像网站,主要用于PPC的推广,这时候就要想办法阻止搜索引擎蜘蛛对我们镜像网站的所有页面进行抓取和索引。因为如果镜像网站也被搜索引擎收录,很可能会影响官网在搜索引擎中的权重。
下面列举几种阻止主流搜索引擎爬虫(蜘蛛)抓取/索引/收录网页的思路。注:全网站屏蔽,尽可能屏蔽主流搜索引擎的所有爬虫(蜘蛛)。
1.被文件阻止
可以说文件是最重要的渠道(可以和搜索引擎建立直接对话),给出以下建议:
用户代理:Baiduspider
不允许:/
用户代理:Googlebot
不允许:/
用户代理:谷歌机器人手机
不允许:/
用户代理:谷歌机器人图像
不允许:/
用户代理:Mediapartners-Google
不允许:/
用户代理:Adsbot-Google
不允许:/
用户代理:Feedfetcher-Google
不允许:/
用户代理:雅虎!大声地吃
不允许:/
用户代理:雅虎!啜饮中国
不允许:/
用户代理:雅虎!-广告爬虫
不允许:/
用户代理:有道机器人
不允许:/
用户代理:Sosospider
不允许:/
用户代理:网络蜘蛛
不允许:/
用户代理:网络网络蜘蛛
不允许:/
用户代理:MSNBot
不允许:/
用户代理:ia_archiver
不允许:/
用户代理:番茄机器人
不允许:/
用户代理:*
不允许:/
2.按元标签屏蔽
将以下语句添加到所有网页头文件中:
3.通过服务器的配置文件来设置(比如Linux/nginx)
直接过滤蜘蛛/机器人的IP段。
注意:第一、二项措施只对“君子”有效,第三项措施要用来防“小人”(“君子”和“小人”一般分别指遵守协议的蜘蛛/机器人)。所以网站上线后,需要跟踪分析日志,筛选出这些badbot的ip,然后进行屏蔽。
什么网页爬虫爬不到?
被引擎K过的网站,爬虫是不会去爬的,因为已经进了黑名单还有一个就是还没被蜘蛛发现未被收录的网站,也是爬不到的
如何吸引搜索引擎蜘蛛抓取我们的网站_?
做网站优化的的目的,就是为了在搜索引擎中,拥有一个良好的排名,从而获得大量的流量。想要在搜索引擎中获得良好的排名,就必须要提升搜索引擎蜘蛛对网站的抓取速度。如果搜索引擎对网站抓取的频率低,就会直接影响到网站的排名、流量以及权重的评级。
那么,如何提升搜索引擎蜘蛛对网站的抓取速度呢?
1、主动提交网站链接
当更新网站页面或者一些页面没被搜索引擎收录的时候,就可以把链接整理后,提交到搜索引擎中,这样可以加快网站页面被搜索引擎蜘蛛抓取的速度。
2、优质的内容
搜索引擎蜘蛛是非常喜欢网站优质的内容,如果网站长时间不更新优质的内容,那么搜索引擎蜘蛛就会逐渐降低对网站的抓取率,从而影响网站排名以及流量。所以网站必须要定时定量的更新优质内容,这样才能吸引搜索引擎蜘蛛的抓取,从而提升排名和流量。
3、网站地图
网站地图可以清晰的把网站内所有的链接展现出来,而搜索引擎蜘蛛可以顺着网站地图中的链接进入到每个页面中进行抓取,从而提升网站排名。
4、外链建设
高质量外链对提升网站排名有很大作用,搜索引擎蜘蛛会顺着链接进入到网站中,从而提升抓取网站的速度。如果外链质量太差,也会影响搜索引擎蜘蛛的抓取速度。
总之,只要提升搜索引擎蜘蛛对网站的抓取速度,网站就能在搜索引擎中获得良好排名,从而获得大量流量。
外链关键词: 泳装模特 骨盆前倾判断方法 珠海市干部培训网 墨尔本建筑专业好吗 大学专业工商管理 永久激活win8.1专业版 刘嘉玲艺术照片丰 一嗨租车本文地址: https://www.q16k.com/article/017426c8eca6a5834420.html

99DNS解析采用独立研发的高性能DNS内核,全球部署DNS集群节点,多线路解析支持电信、联通、移动等12条线路、按用户所在地等细分形式划分解析线路。向全网域名提供免费的智能解析服务,同时还提供专业的DNS防御方案,保障域名解析的快速、稳定、安全.

电脑狂人,一个免费分享电脑技术,绿色软件的网站。如果你感觉不错的话,欢迎分享给你的朋友!
韩饭网是一家专注于韩娱分享的中文网站,为用户24小时提供全面及时的韩国娱乐资讯,内容包含韩国电视剧、韩国电影、韩国综艺、节目表、音乐演出和明星时尚,让您掌握第一手娱乐圈动态。
21世纪商业评论

w7ghost手游提供最新最热的手机游戏,让每位玩家都了解当下最热门的手机游戏,能安全高速的下载到喜欢的手机游戏,同时也推荐常用和好用的手机软件APP。
通过手机扫描借贷宝二维码登录的方式,轻松实现借贷宝在线充值,了解借贷宝充值限额等内容。借贷宝手机借贷软件旨在提供高效、灵活、极速的掌上金融交易平台
好文章阅读网为你提供经典文章,美文,伤感日志,伤感文章,爱情情感文章等情感日志,欣赏网络经典美文,情感美文,伤感美文摘抄等美文欣赏,文章阅读网欢迎你的光临!

泡泡影视为您提供最近好看的电视剧,最新电影,还为您整理了最新影视资讯、明星大全、电视剧演员表、电视剧剧情等影视相关内容,最近好看的电影电视剧
宇宇阅读网是在线阅读网站有阅读的好处,短文分类,作家小说集,热门小说,传记,励志,古典文学等。
该站点未添加描述description...
该站点未添加描述description...

福州公交查询,福州公交线路查询,福州公交地图,福州市公交,福州公交车查询路线,公交车线路查询,福州公交网,福州公交数据实时更新。

该站点未添加描述description...
该站点未添加描述description...

资享网为网友分享上传的涵盖各行各业的专业资料打包下载网站,本站特色为所有资料可在线免费全文预览,本站专注于上传分享、预览、下载文件的专业打包网站,内容不求广而多,只求精而美,资料力求科学、权威性。
该站点未添加描述description...
星座查询为您提供十二星座的性格特点、爱情观、优缺点和事业观运势分析,对各星座男女逐个运势解析,让您跟了解自己的人生命运。

该站点未添加描述description...


在接手一个网站时,无论做什么诊断分析,都少不了检查robots文件,为什么有的网站天天发文章却未见收录,很有可能是因为被robots文件里的规则屏蔽搜索引擎抓取所导致的。那么什么是robots文件,对于一个网站它的作用的什么?本文白天为你详细介绍robots文件并教你robots文件正确的写法。图1robots文件一、robots文件...
有时候有些页面访问消耗性能比较高不想让搜索引擎抓取,可以在根目录下放robots.txt文件屏蔽搜索引擎或者设置搜索引擎可以抓取文件范围以及规则。Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(RobotsExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面...

相信做过网站优化的朋友都听过robots文件和,但是大家真正清楚它们的作用与用途吗?不瞒大家说,白天也经常犯迷糊,好像他们的作用是一样的。但这真的只是好像,它们的不同点反而很多。那么本篇文章白天就来给大家讲讲经过多次研究后,说说白天对robots与nofollow的理解。首先先从它们的定义开始:robots在网站里通常是指robots...

搜索引擎可以通过这个时间来快速抓取到近期有改动的网页有哪些,通过与之前的索引数据对比即可起到快速更新的作用。而如果没有上次改变时间,则搜索引擎只能通过抓取或者其他途经来了解网站改动内容吗,与在sitemap文件相比,肯定是sitemap文件里声明修改时间更有效。Sitemap是什么?作用是什么?sitemap被搜索引擎用来了解网站内部...

在接手一个网站时,无论做什么诊断剖析,都少不了审核robots文件,为什么有的网站天天发文章却未见收录,很有或许是由于被robots文件里的规则屏蔽搜查引擎抓取所造成的。那么什么是robots文件,关于一个网站它的作用的什么?本文白昼为你详细引见robots文件并教你robots文件正确的写法。图1robots文件一、robots文件...

我们都知道网站想要有排名必须要先增加百度收录,同时标题要包含指数关键词,这样才可以提高第三方平台的百度权重值,我们在交换友链时收录数量也是一个交换的标准,比如你的网站收录是一万,我想你不会跟收录只有100的网站做链接。新网站想要增加百度收录除了内容要优质外,还要通过外部链接引蜘蛛到访,并且网站的robots文件没有拒绝蜘蛛爬行,日更文...
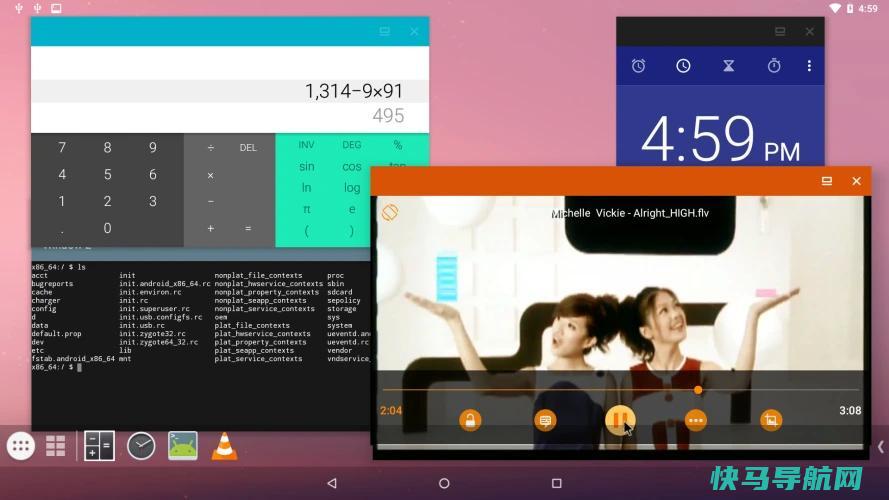
有没有想过你能在电脑上运行安卓应用程序?你希望你的Android游戏不会被降级到这么小的手机屏幕上吗?也许你需要在Android上测试一项功能,但没有合适的设备,或者你只是想在一款原本停留在移动设备上的应用程序上获得那种大屏幕体验。你的选择将取决于你拥有的移动设备或你运行的Windows版本,但有几种方法可以在你的电脑上运行Andro...
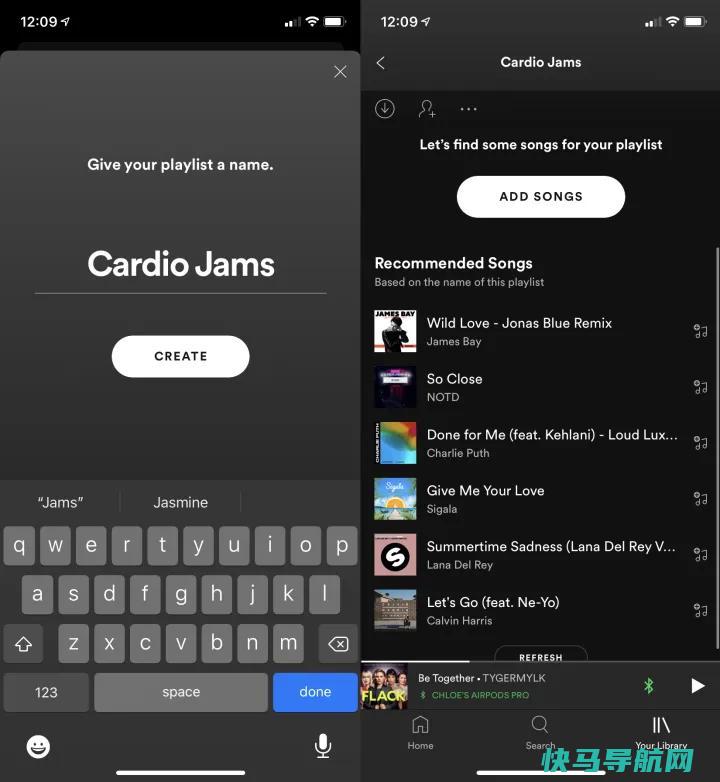
SpotifyPremium以每月不到10美元的价格将8000多万首曲目放在你的指尖(这令人懊恼一些音乐专业人士)。但不管你喜不喜欢,流媒体已经接管了音乐行业,它的统治地位始于总部位于斯德哥尔摩的Spotify,也结束于它的统治。这家音乐流媒体服务在过去几年里发生了相当大的变化,变得更具预测性和个性化,同时吸引了越来越多的音乐和播客内...
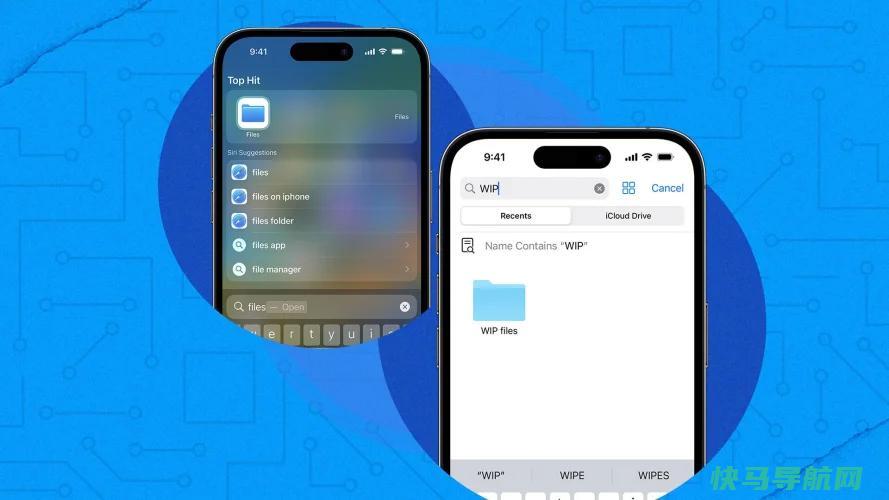
苹果的Files应用程序可以让你在一个地方查看和管理存储在iCloudDrive、Box、Dropbox、GoogleDrive和MicrosoftOneDrive等在线服务上的文件。你还可以查看直接存储在iPhone或iPad上的文件,并对它们运行各种命令。随着iOS和iPadOS的每一个新版本,苹果都会为Files应用程序增添一些...

Instagram上的故事很容易创作,但如果你想让它们真正具有娱乐性,就需要花很多心思。值得庆幸的是,Meta提供了许多工具来帮助您的故事尽可能地有趣,包括滤镜和贴纸。然而,你的故事可能仍然缺少一个重要的元素:音乐。Instagram允许你添加自己库中的歌曲或你最喜欢的音乐流媒体服务,如Spotify、SoundCloud和Shaza...

大家好,主动隔离是自费还是免费相信很多的网友都不是很明白,包括隔离需要自费吗知乎也是一样,不过没有关系,接下来就来为大家分享关于主动隔离是自费还是免费和隔离需要自费吗知乎的一些知识点,大家可以关注收藏,免得下次来找不到哦,下面我们开始吧!本文目录一、主动报备隔离要收费吗1、提前24小时向目的地所在社区(村)报备,并按照要求落实全程闭环...