 用户中心
用户中心robots文件引见、作用及写法
在接手一个网站时,无论做什么诊断剖析,都少不了审核 robots文件 ,为什么有的网站天天发文章却未见收录,很有或许是由于被robots文件里的规则屏蔽搜查引擎抓取所造成的。那么什么是robots文件,关于一个网站它的作用的什么?本文白昼为你详细引见robots文件并教你robots文件正确的写法。

一、robots文件简介
繁难来说就是一个以robots命名的txt格局的文本文件,是网站跟爬虫间的协定(你可以了解为搜查引擎蜘蛛抓取的规则),当搜查引擎发现一个新的站点时,首先会审核该站点能否存在robots文件,假设存在,搜查引擎则会跟据robots文件规则的规则来确定可以访问该站点的范畴。
二、robots文件的作用
1.制止搜查引擎收录网站,以保证网站的安保。比如一些网站是客户治理系统,只要要公司员工登录即可,属于并不想地下的私密消息,为了防止消息暴露就可以经常使用robots文件启动屏蔽抓取。
2.网站内的局部目录或内容假设不宿愿搜查引擎抓取,如WordPress的后盾文件 wp-admin,治理仪表盘或其余页面,这些对搜查引擎无用的页面就可以借助robots文件来通知搜查引擎不要抓取此目录下的内容,这样就可以让有限带宽的蜘蛛深化抓取更多须要被抓取收录的页面。
3.屏蔽一些灵活链接,一致网站链接类型,集中权重。
三、robots文件写法
1、首先先来了解下robots文件里的内容由那几局部造成:
一个robots文件,不同的写法有不同的意义,经常出现的robots文件由User-agent、Allow、Disallow 等组成。另外,咱们也经常会在robots文件中参与网站 sitemap 文件的链接以疏导搜查引擎爬虫抓取。举一个例子:
User-agent: Baiduspider Allow: /wp-content/uploads/ Disallow: /w? Sitemap: HTTPS:/www.seobti.com/sitemap.xml
该例子中就蕴含有User-agent、Allow、Disallow 、Sitemap等。上方详细来解释下各自的作用。
User-agent: 该项的值用于形容搜查引擎robot的名字。在robots.txt文件中,至少要有一条User-agent记载。假设该项的值设为*(即:“User-agent:*”),则对任何robot均有效。另外假设只针对百度搜查引擎,则该项的值为:Baiduspider(即:“User-agent:Baiduspider”)。
该项的值用于形容不宿愿被访问的一组URL,这个值可以是一条完整的门路,也可以是门路的非绝后缀,以Disallow项的值扫尾的URL不会被 robot访问。
举例说明:
该项的值用于形容宿愿被访问的一组URL,与Disallow项相似,这个值可以是一条完整的门路,也可以是门路的前缀,以Allow项的值扫尾的URL 是准许robot访问的。
举例说明:
以上是sitemap组成经常出现的局部,为了让robots写法更准确,咱们还可以经常使用借助“”and “”来更准确的制订搜查引擎抓取规则。
:robots文件中可以经常使用通配符“*”和“$”来含糊婚配url。“*” 婚配0或多个恣意字符, “$” 婚配行完结符。
举例说明:
2、格局
在robots文件中,一个“
User-agent
”代表一条记载,且这样的记载可以蕴含一条或多条记载。如:
一条记载
User-agent: * Disallow: /template/ #该协定只要一条记载,该协定对一切搜查引擎有效
多条记载
User-agent: Baiduspider Disallow: /w? Disallow: /client/User-agent: Googlebot Disallow: /update Disallow: /historyUser-agent: bingbot Disallow: /usercard#多条记载,针对不同的搜查引擎经常使用不同的协定
留意
:“
User-agent: *
”中的“*”是通配符的意思, 也就是说该记载下的协定实用任何搜查引擎,而“
User-agent: Baiduspider
”中的“Baiduspider”是百度搜查引擎的爬取程序称号,也就是该协定只针对百度搜查引擎。
普通来说,优化的对象假设只针对国际的用户,那么就可以经常使用多条记载的模式来限度国外搜查引擎的抓取,以此可以节俭主机局部资源,减小主机压力。
另外须要留意的是: robots.txt文件中只能有一条 “User-agent: *”这样的记载。
3、语法说明
这里关键罗列几种比拟经常出现的写法,如图2所示:

4、注释
为了繁难了解,咱们可以在robots文件里参与注释,在每一行以“ # ”扫尾即可(相似于主机性能文件中的写法规则)。如图3所示:

四、经常使用robots文件须要留意的一些事项
1、robots文件应放在网站根目录,链接地址为:www.xxx.com/robots.txt;
2、鉴于不宿愿搜查引擎收录网站的隐衷文件,可以经常使用robots文件来制止抓取,但这样却正好可以被黑客所应用, 所以robots文件并不能保证网站的隐衷,因此在robots规则时,可以经常使用“*”来含糊婚配。 如:Disallow:/my*;
3、“
Disallow: /help
”与“
Disallow: /help/
”规则的抓取范畴有所不同,“/help”蕴含“/help.html、/help*.html、/help/index.html”等页面,而“/help/”不蕴含“/help.html、/help*.html”等页面。
五、robots的其余用法
除了经常使用 robots.txt 来告知搜查引擎哪些页面能被抓取,哪些页面不能被抓取外,robots还有另外一些写法—— Robots meta 标签。
Robots.txt文件关键是限度整个站点或许目录的搜查引擎访问状况,而Robots Meta标签则关键是针对一个个详细的页面。和其余的META标签(如经常使用的言语、页面的形容、关键词等)一样,Robots Meta标签也是放在页面中,专门用来通知搜查引擎爬虫如何抓取该页的内容。
Robots Meta标签中没有大小写之分,
name="robots"
示意一切的搜查引擎,可以针对某个详细搜查引擎写为
name="BaiduSpider"
。
content局部有四个指令选项:index、noindex、follow、nofollow,指令间以“,”分隔。
详细写法有以下四种:
其中:
可以写成
而
可以写成
另外驰名搜查引擎 Google 还参与了一个指令“archive”,可以限度Google能否保管网页快照。例如:
须要留意的是并不是一切的搜查引擎都支持Robots meta标签写法。
过去的当天:
robots文件SEO术语原创文章,作者:白昼,如若转载请注明出处:robots文件引见、作用及写法
网站的Robots规则如何写才正确? Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些死链接。 方便搜索引擎抓取网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。 下面是Robots文件写法及文件用法。 一、文件写法 User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符 Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录 Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录 Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录 Disallow: /cgi-bin/* 禁止访问/cgi-bin/目录下的所有以为后缀的URL(包含子目录)。 Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址 Disallow: /$ 禁止抓取网页所有的。 jpg格式的图片 Disallow:/ab/ 禁止爬取ab文件夹下面的文件。 Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录 Allow: /tmp 这里定义是允许爬寻tmp的整个目录 Allow: $ 仅允许访问以为后缀的URL。 Allow: $ 允许抓取网页和gif格式图片 Sitemap: 网站地图 告诉爬虫这个页面是网站地图 二、文件用法 例1. 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 实例分析:淘宝网的 文件 User-agent: Baiduspider Disallow: / User-agent: baiduspider Disallow: / 很显然淘宝不允许网络的机器人访问其网站下其所有的目录。 例2. 允许所有的robot访问 (或者也可以建一个空文件 “/” file) User-agent: * Allow: / 例3. 禁止某个搜索引擎的访问 User-agent: BadBot Disallow: / 例4. 允许某个搜索引擎的访问 User-agent: Baiduspider allow:/ 例5.一个简单例子 在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。 需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。 User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*”这样的记录出现。 User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ Robot特殊参数: 允许 Googlebot: 如果您要拦截除Googlebot以外的所有漫游器不能访问您的网页,可以使用下列语法: User-agent: Disallow: / User-agent: Googlebot Disallow: Googlebot 跟随指向它自己的行,而不是指向所有漫游器的行。 “Allow”扩展名: Googlebot 可识别称为“Allow”的 标准扩展名。 其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。 “Allow”行的作用原理完全与“Disallow”行一样。 只需列出您要允许的目录或页面即可。 您也可以同时使用“Disallow”和“Allow”。 例如,要拦截子目录中某个页面之外的其他所有页面,可以使用下列条目: User-agent: Googlebot Allow: /folder1/ Disallow: /folder1/ 这些条目将拦截 folder1 目录内除 之外的所有页面。 如果您要拦截 Googlebot 并允许 Google 的另一个漫游器(如 Googlebot-Mobile),可使用”Allow”规则允许该漫游器的访问。 例如: User-agent: Googlebot Disallow: / User-agent: Googlebot-Mobile Allow: 使用 * 号匹配字符序列: 您可使用星号 (*) 来匹配字符序列。 例如,要拦截对所有以 private 开头的子目录的访问,可使用下列条目: User-Agent: Googlebot Disallow: /private*/ 要拦截对所有包含问号 (?) 的网址的访问,可使用下列条目: User-agent: * Disallow: /*?* 使用 $ 匹配网址的结束字符 您可使用 $字符指定与网址的结束字符进行匹配。 例如,要拦截以 结尾的网址,可使用下列条目: User-agent: Googlebot Disallow: /*$ 您可将此模式匹配与 Allow 指令配合使用。 例如,如果 ? 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。 但是,以 ? 结尾的网址可能是您要包含的网页版本。 在此情况下,可对 文件进行如下设置: User-agent: * Allow: /*?$ Disallow: /*? Disallow: / *? 一行将拦截包含 ? 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (?),而后又是任意字符串的网址)。 Allow: /*?$ 一行将允许包含任何以 ? 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (?),问号之后没有任何字符的网址)。 Robots协议举例 禁止所有机器人访问User-agent:*Disallow:/ 允许所有机器人访问User-agent:*Disallow: 禁止特定机器人访问User-agent:BadBotDisallow:/ 允许特定机器人访问User-agent:GoodBotDisallow: 禁止访问特定目录User-agent:*Disallow:/images/ 仅允许访问特定目录User-agent:*Allow:/images/Disallow:/ 禁止访问特定文件User-agent:*Disallow:/*$ 仅允许访问特定文件User-agent:*Allow:/*$Disallow:/ 尽管已经存在很多年了,但是各大搜索引擎对它的解读都有细微差别。 Google与网络都分别在自己的站长工具中提供了robots工具。 如果您编写了文件,建议您在这两个工具中都进行测试,因为这两者的解析实现确实有细微差别。 更多青晟网络资讯请登录官方网站:或者
robots的写法有哪些呢?
一、定义 是存放在站点根目录下的一个纯文本文件,让搜索蜘蛛读取的txt文件,文件名必须是小写的“”。 二、作用:通过可以控制搜索引擎收录内容,告诉蜘蛛哪些文件和目录可以收录,哪些不可以收录。 三、语法: User-agent:搜索引擎的蜘蛛名 Disallow:禁止搜的内容 Allow:允许搜的内容 四、实例: -agent: * //禁止所有搜索引擎搜目录1、目录2、目录3Disallow: /目录名1/ Disallow: /目录名2/Disallow: /目录名3/ 2. User-agent: Baiduspider //禁止网络搜索secret目录下的内容 Disallow: /secret/ 3. User-agent: * //禁止所有搜索引擎搜索cgi目录,但是允许slurp搜索所有Disallow: /cgi/User-agent: slurp Disallow: 4. User-agent: *//禁止所有搜索引擎搜索haha目录,但是允许搜索haha目录下test目录Disallow: /haha/ Allow:/haha/test/ 五、常见搜索引擎蜘蛛的代码#搜索引擎User-Agent代码对照表以上是使用方法,更多的到yy6359频道学习吧
什么是robots协议?网站中的写法和作用
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。 文件写法User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录Disallow: /cgi-bin/* 禁止访问/cgi-bin/目录下的所有以为后缀的URL(包含子目录)。 Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址Disallow: /$ 禁止抓取网页所有的格式的图片Disallow:/ab/ 禁止爬取ab文件夹下面的文件。 Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录Allow: /tmp 这里定义是允许爬寻tmp的整个目录Allow: $ 仅允许访问以为后缀的URL。 Allow: $ 允许抓取网页和gif格式图片Sitemap: 网站地图 告诉爬虫这个页面是网站地图文件用法例1. 禁止所有搜索引擎访问网站的任何部分User-agent: *Disallow: /实例分析:淘宝网的 文件User-agent: BaiduspiderDisallow: /User-agent: baiduspiderDisallow: /很显然淘宝不允许网络的机器人访问其网站下其所有的目录。 例2. 允许所有的robot访问 (或者也可以建一个空文件 “/” file)User-agent: *Allow: /例3. 禁止某个搜索引擎的访问User-agent: BadBotDisallow: /例4. 允许某个搜索引擎的访问User-agent: Baiduspiderallow:/例5.一个简单例子在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。 需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。 User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*”这样的记录出现。 User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Robot特殊参数:允许 Googlebot:如果您要拦截除Googlebot以外的所有漫游器不能访问您的网页,可以使用下列语法:User-agent:Disallow: /User-agent: GooglebotDisallow:Googlebot 跟随指向它自己的行,而不是指向所有漫游器的行。 “Allow”扩展名:Googlebot 可识别称为“Allow”的 标准扩展名。 其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。 “Allow”行的作用原理完全与“Disallow”行一样。 只需列出您要允许的目录或页面即可。 您也可以同时使用“Disallow”和“Allow”。 例如,要拦截子目录中某个页面之外的其他所有页面,可以使用下列条目:User-agent: GooglebotAllow: /folder1/: /folder1/这些条目将拦截 folder1 目录内除 之外的所有页面。 如果您要拦截 Googlebot 并允许 Google 的另一个漫游器(如 Googlebot-Mobile),可使用”Allow”规则允许该漫游器的访问。 例如:User-agent: GooglebotDisallow: /User-agent: Googlebot-MobileAllow:使用 * 号匹配字符序列:您可使用星号 (*) 来匹配字符序列。 例如,要拦截对所有以 private 开头的子目录的访问,可使用下列条目: User-Agent: GooglebotDisallow: /private*/要拦截对所有包含问号 (?) 的网址的访问,可使用下列条目:User-agent: *Disallow: /*?*使用 $ 匹配网址的结束字符您可使用 $字符指定与网址的结束字符进行匹配。 例如,要拦截以 结尾的网址,可使用下列条目: User-agent: GooglebotDisallow: /*$您可将此模式匹配与 Allow 指令配合使用。 例如,如果 ? 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。 但是,以 ? 结尾的网址可能是您要包含的网页版本。 在此情况下,可对 文件进行如下设置:User-agent: *Allow: /*?$Disallow: /*?Disallow: / *?一行将拦截包含 ? 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (?),而后又是任意字符串的网址)。 Allow: /*?$ 一行将允许包含任何以 ? 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (?),问号之后没有任何字符的网址)。 尽管已经存在很多年了,但是各大搜索引擎对它的解读都有细微差别。 Google与网络都分别在自己的站长工具中提供了robots工具。 如果您编写了文件,建议您在这两个工具中都进行测试,因为这两者的解析实现确实有细微差别。
文件要怎么写
大家先了解下文件是什么,有什么作用。 搜索引擎爬去我们页面的工具叫做搜索引擎机器人,也生动的叫做“蜘蛛”蜘蛛在爬去网站页面之前,会先去访问网站根目录下面的一个文件,就是。 这个文件其实就是给“蜘蛛”的规则,如果没有这个文件,蜘蛛会认为你的网站同意全部抓取网页。 文件是一个纯文本文件,可以告诉蜘蛛哪些页面可以爬取(收录),哪些页面不能爬取。 举个例子:建立一个名为的文本文件,然后输入User-agent: * 星号说明允许所有搜索引擎收录Disallow: ? 表示不允许收录以?前缀的链接,比如?=865Disallow: /tmp/ 表示不允许收录根目录下的tmp目录,包括目录下的文件,比如tmp/具体使用方法网络和谷歌都有解释,网络文件可以帮助我们让搜索引擎删除已收录的页面,大概需要30-50天。
新手SEO具体操作必须怎么写robots文件。
做SEO时,最好是把文件写好,下面说下写法:
搜索引擎Robots协议:是放置在网站根目录下文本文件,在文件中可以设定搜索引擎蜘蛛爬行规则。设置搜索引擎蜘蛛Spider抓取内容规则。
下面是robots的写法规则与含义:
首先要创建一个文本文件,放置到网站的根目录下,下面开始编辑设置Robots协议文件:
一、允许所有搜索引擎蜘蛛抓取所以目录文件,如果文件无内容,也表示允许所有的蜘蛛访问,设置代码如下:
User-agent:*...
浅析网站Robots协议语法及使用
每个人都有自己的隐私,每个网站也都有隐私;人可将隐私藏在心底,网站可以用robots进行屏蔽,让别人发现不了,让蜘蛛无法抓取,小蔡简单浅析下Robots协议语法及在SEO中的妙用,对新手更好理解及把握!什么是Robots协议?Robots协议(也称为爬虫协议、机器人协议等)是约束所有蜘蛛的一种协议。 搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息。 您可以在您的网站中创建一个纯文本文件,网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。 作用1、屏蔽网站内的死链接。 2、屏蔽搜索引擎蜘蛛抓取站点内重复内容和页面。 3、阻止搜索引擎索引网站隐私性的内容。 (例如用户账户信息等)放在哪?文件应该放置在网站根目录下(/)。 举例来说,当spider访问一个网站(比如)时,首先会检查该网站中是否存在这个文件,如果 Spider找到这个文件,它就会根据这个文件内容的规则,来确定它访问权限的范围。 Robots写法Robots一般由三个段和两个符号组成,看个人需求写规则。 最好是按照从上往下的顺序编写(由实践证明这顺序影响不大)。 三个字段(记得“:”后面加空格)User-agent: 用户代理 Disallow:不允许Allow:允许(/ 代表根目录,如 Allow: /允许所有)两个符号星号 * 代表所有0-9 A-Z #通配符 $ 以某某个后缀具体用法:例1. 禁止所有搜索引擎访问网站的任何部分User-agent: *Disallow: /例2. 允许所有的robot访问(或者也可以建一个空文件 /)User-agent: *Disallow:或者User-agent: *Allow: /例3. 仅禁止Baiduspider访问您的网站User-agent: BaiduspiderDisallow: /禁止访问/cgi-bin/目录下的所有以为后缀的URL(包含子目录)。 User-agent: *Disallow: /cgi-bin/*$例4.禁止Baiduspider抓取网站上所有图片;仅允许抓取网页,禁止抓取任何图片。 User-agent: BaiduspiderDisallow: $Disallow: $Disallow: $Disallow: $Disallow: $例5.仅允许Baiduspider访问您的网站User-agent: BaiduspiderDisallow:User-agent: *Disallow: /例6.允许访问特定目录中的部分url(根据自己需求定义)User-agent: *Allow: /cgi-bin/seeAllow: /tmp/hiAllow: /~joe/lookDisallow: /cgi-bin/例7.不允许asp后缀User-agent: *Disallow: /*
外链关键词: 德州康宝莱经销商地址电话 无边框拼图软件 广东专升本上岸心得 康宝莱从此人生更精彩片段 自考专升本统考 往届毕业生认证学历怎么填 屋面工程技术交底 专升本暑假怎么自学本文地址: https://www.q16k.com/article/131f72cbde11c447c311.html

The #1 source for fashion inspiration from real people around the world. Community “hype” promotes looks to the front page.

伪装资源站(WEIZHUANG68.CN)专注站长资源以及网站源码下载、网站模板下载,为建站开发人员提供优质的一站式服务平台。

百度热搜以数亿用户海量的真实数据为基础,通过专业的数据挖掘方法,计算关键词的热搜指数,旨在建立权威、全面、热门、时效的各类关键词排行榜,引领热词阅读时代。
小学生日记大全网,提供小学生一年级、二年级、三年级、四年级、五年级、六年级日记,以及日记50字,100字,200字,300字,400字,500字,等小学生日记。
周金生珠宝
数据分析,matomo,matovba
该站点未添加描述description...
贵阳传媒网
该站点未添加描述description...
该站点未添加描述description...
大婷电子YA宠物网汇集了关于宠物用品,宠物,宠物零食,猫粮,狗粮,宠物食品,宠物罐头等资讯,欢迎各位热爱动物的人士前来学习交流。

该站点未添加描述description...
该站点未添加描述description...
万年历,日历,历史上的今天,节日,农历,查询
一个有温度的PaaS平台
该站点未添加描述description...
童话镇里一枝花, 人美歌甜陈一发.
鼎捷TIPTOP-T100-易拓-易飞ERP系统交流论坛


在接手一个网站时,无论做什么诊断分析,都少不了检查robots文件,为什么有的网站天天发文章却未见收录,很有可能是因为被robots文件里的规则屏蔽搜索引擎抓取所导致的。那么什么是robots文件,对于一个网站它的作用的什么?本文白天为你详细介绍robots文件并教你robots文件正确的写法。图1robots文件一、robots文件...

有时候有些页面访问消耗性能比较高不想让搜索引擎抓取,可以在根目录下放robots.txt文件屏蔽搜索引擎或者设置搜索引擎可以抓取文件范围以及规则。Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(RobotsExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面...

相信做过网站优化的朋友都听过robots文件和,但是大家真正清楚它们的作用与用途吗?不瞒大家说,白天也经常犯迷糊,好像他们的作用是一样的。但这真的只是好像,它们的不同点反而很多。那么本篇文章白天就来给大家讲讲经过多次研究后,说说白天对robots与nofollow的理解。首先先从它们的定义开始:robots在网站里通常是指robots...
在接手一个网站时,无论做什么诊断剖析,都少不了审核robots文件,为什么有的网站天天发文章却未见收录,很有或许是由于被robots文件里的规则屏蔽搜查引擎抓取所造成的。那么什么是robots文件,关于一个网站它的作用的什么?本文白昼为你详细引见robots文件并教你robots文件正确的写法。图1robots文件一、robots文件...

我们都知道网站想要有排名必须要先增加百度收录,同时标题要包含指数关键词,这样才可以提高第三方平台的百度权重值,我们在交换友链时收录数量也是一个交换的标准,比如你的网站收录是一万,我想你不会跟收录只有100的网站做链接。新网站想要增加百度收录除了内容要优质外,还要通过外部链接引蜘蛛到访,并且网站的robots文件没有拒绝蜘蛛爬行,日更文...
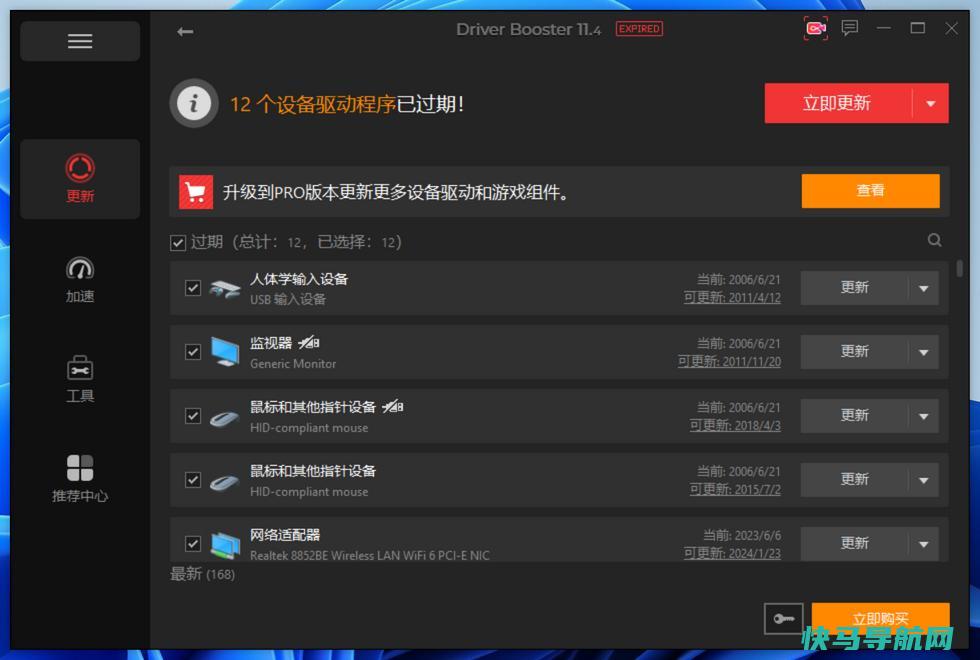
驱动管理新选择:借助DriverBooster解决驱动疑难杂症DriverBooster是一款为Windows用户设计的强大驱动更新工具,能自动检测并更新过时的驱动程序。它支持超过650万种设备驱动,能快速解决各种驱动相关的问题,从而提高系统的稳定性和性能。前言最近,xiaoz在尝试使用蓝牙鼠标时遇到了电脑无法识别设备的问题。怀疑是驱...
微软今天将在其最新的Windows11InsiderBetaChannel版本中加入几个重要功能,这表明它致力于更新RGB照明控制、更新的文件资源管理器以及微妙但巧妙的墨水改进。微软今天向WindowsInsiderBeta频道发布了Windows11Insider预览版22621.2050和22631.2050。从历史上看,通过Be...

世界上最大的科技展即将到来,NVIDIA以一些重磅GPU揭开了CES2023赛前公告的序幕。该公司新的GeForceRTX40系列显卡即将进入笔记本电脑-包括有史以来第一次的旗舰RTX4090-以及该公司的GeForceNow服务,令人惊讶!GeForceRTX4070钛是真实的,将于1月5日发布。不过,我们以前见过这种显卡。这场展示...

如果你的一天工作很辛苦,考虑一下情况可能会更糟。例如,AMD授权厂商PowerColor的某个人现在正处于痛苦之中,因为该公司不小心发布了RadeonRX7800XT显卡的完整清单,包括规格。这款图形处理器听起来是不是很陌生?这可能是因为RadeonRX7800XT还没有正式存在。哎呀。自去年推出以来,AMD的Radeon7000系列...

20世纪90年代,一位同事带我去了台北的红灯区“蛇巷”,与“艺人”和他们的一些肌肉发达、严肃的朋友们畅饮了一晚。幸运的是,大家都玩得很开心。尽管如此,我年轻、愚蠢,也很幸运,我没有遇到任何麻烦。互联网的某些部分也是这样的。如果你认为你可能会进入一个危险的互联网社区–山寨购物网站、鲜为人知的流媒体服务,或者你只是不完全确定是否合法的地方...