 用户中心
用户中心robots与nofollow的区别是什么?怎样使用才算正确?
相信做过网站优化的朋友都听过 robots文件 和,但是大家真正清楚它们的作用与用途吗?不瞒大家说,白天也经常犯迷糊,好像他们的作用是一样的。但这真的只是好像,它们的不同点反而很多。那么本篇文章白天就来给大家讲讲经过多次研究后,说说白天对robots与nofollow的理解。

首先先从它们的定义开始:
robots在网站里通常是指 robots文件 ,是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉爬虫网站可以访问的部分以及不可以访问的部分。换句话说就是,可爬取的部分是允许被收录,而不允许爬取的部分是不允许被收录的。
nofollow是HTML页面中a标签的属性值,用于告诉搜索引擎不要追踪特定的网页链接。举个例子,如A网页上有一个链接指向B网页,在A网页上给这个链接加上了 rel=”nofollow” ,这时当搜索引擎抓取到A网页时,A网页不算入B网页的反向链接。搜索引擎看到这个标签就可能减少或完全取消链接的投票权重,避免权重流失,因此nofollow常用于网站上的出站链接。
至于为什么白天会认为它们相同,是因为:robots文件和nofollow都可以用来屏蔽一些不想被爬虫抓取的链接。
但仔细一想,两者确实存在很多不同,各有各的优劣势。如:
1、nofollow属性主要用于禁止搜索引擎跟踪网站某条链接。当一个页面我们希望它正常被收录获得排名,但是因为有的页面中关于此链接的重复链接太多了,这时候就不适合用“robots”来屏蔽了,而是应该使用“nofollow”标签对部分重复链接进行屏蔽。
另外对于不想被收录的页面,这种情况下如果使用nofollow来进行屏蔽的话,你会发现网站维护起来会异常麻烦,因为网站中的新页面难免有的石斛需要加上该链接,每加一次都要另外加一次“nofollow”标签,一旦有一次遗漏了,就很有可能会被搜索引擎给收录了。因此,虽说nofollow属性也可以屏蔽搜索引擎对于网站动态链接的爬取,但效果不如robots协议文件。毕竟当网页里
2、Robots协议文件主要作用是可以通过规则来批量屏蔽网站页面里的动态链接,不让搜索引擎蜘蛛抓取这里的动态链接路径。此外,也可以屏蔽掉一些低质量的页面或链接。但是robots文件只针对网站自身的页面有效,不能屏蔽站内导出的外部链接,而“nofollow”没有这个限制,这也是nofollow和robots比较重要的一个区别。
3、nofollow只能做到减少投票权重的流失。虽说我们对一些不希望被抓取的链接加了nofollow,但这个链接同样会被搜索引擎抓取并收录。而robots则直接告诉搜索引擎不要收录这个链接,但凡遇到这个链接页面,你都不要再多事了,也不要抓取这个页面的内容。
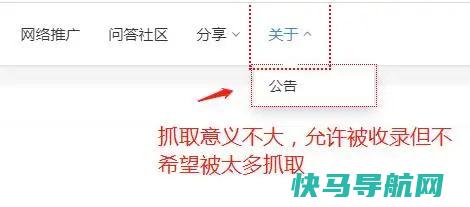
正确使用robots和nofollow属性
对于站内不希望被抓取的链接(如网站后台路径、动态链接),推荐使用robots文件;
对于单个网页内,不希望某些链接被抓取以增加其他希望被抓取的机会(如多次出现的链接,或不是那么重要不需要参与排名的链接),推荐使用nofollow。
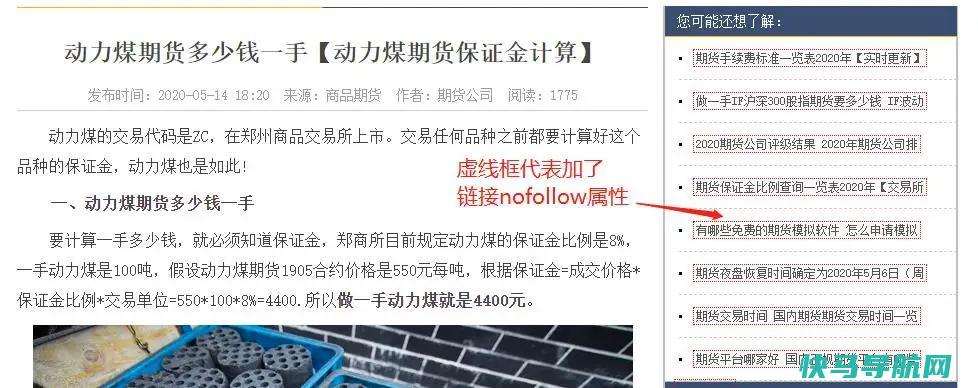
nofollow的进阶用法:对于一些需要参与排名的页面,当我们希望这个页面减少权重导出时,可以适当对该页面上的一些链接添加nofollow。比如:文章页侧边栏的内容大多数情况是用来推荐一些与文章内容不相关的文章,那么这些文章除了给用户看外,其实际意义并不大,那么我们就可以将这些推荐文章的链接添加nofollow属性,以减少文章页导出到其他页的权重。参考图:
结语:看来这篇关于“区分fobots与nofollow”的文章,也不知道大家能不能明白些。像白天始终没有绕过这个弯来,干脆直接给不想被抓取或参与排名的页面,管它robots还是nofollow,一顿操作能加的都给它安排上,哈哈!
过去的今天:
robots文件原创文章,作者:白天,如若转载请注明出处: robots与nofollow的区别是什么?怎样使用才算正确?
nofollow标签怎么用?
nofollow标签通常有两种使用方法: 1、将nofollow写在网页上的meta标签上,用来告诉搜索引擎不要抓取网页上的所有外部链接。
网站的Robots规则如何写才正确?
网站的Robots规则如何写才正确? Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些死链接。 方便搜索引擎抓取网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。 下面是Robots文件写法及文件用法。 一、文件写法 User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符 Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录 Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录 Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录 Disallow: /cgi-bin/* 禁止访问/cgi-bin/目录下的所有以为后缀的URL(包含子目录)。 Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址 Disallow: /$ 禁止抓取网页所有的。 jpg格式的图片 Disallow:/ab/ 禁止爬取ab文件夹下面的文件。 Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录 Allow: /tmp 这里定义是允许爬寻tmp的整个目录 Allow: $ 仅允许访问以为后缀的URL。 Allow: $ 允许抓取网页和gif格式图片 Sitemap: 网站地图 告诉爬虫这个页面是网站地图 二、文件用法 例1. 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 实例分析:淘宝网的 文件 User-agent: Baiduspider Disallow: / User-agent: baiduspider Disallow: / 很显然淘宝不允许网络的机器人访问其网站下其所有的目录。 例2. 允许所有的robot访问 (或者也可以建一个空文件 “/” file) User-agent: * Allow: / 例3. 禁止某个搜索引擎的访问 User-agent: BadBot Disallow: / 例4. 允许某个搜索引擎的访问 User-agent: Baiduspider allow:/ 例5.一个简单例子 在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。 需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。 User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*”这样的记录出现。 User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ Robot特殊参数: 允许 Googlebot: 如果您要拦截除Googlebot以外的所有漫游器不能访问您的网页,可以使用下列语法: User-agent: Disallow: / User-agent: Googlebot Disallow: Googlebot 跟随指向它自己的行,而不是指向所有漫游器的行。 “Allow”扩展名: Googlebot 可识别称为“Allow”的 标准扩展名。 其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。 “Allow”行的作用原理完全与“Disallow”行一样。 只需列出您要允许的目录或页面即可。 您也可以同时使用“Disallow”和“Allow”。 例如,要拦截子目录中某个页面之外的其他所有页面,可以使用下列条目: User-agent: Googlebot Allow: /folder1/ Disallow: /folder1/ 这些条目将拦截 folder1 目录内除 之外的所有页面。 如果您要拦截 Googlebot 并允许 Google 的另一个漫游器(如 Googlebot-Mobile),可使用”Allow”规则允许该漫游器的访问。 例如: User-agent: Googlebot Disallow: / User-agent: Googlebot-Mobile Allow: 使用 * 号匹配字符序列: 您可使用星号 (*) 来匹配字符序列。 例如,要拦截对所有以 private 开头的子目录的访问,可使用下列条目: User-Agent: Googlebot Disallow: /private*/ 要拦截对所有包含问号 (?) 的网址的访问,可使用下列条目: User-agent: * Disallow: /*?* 使用 $ 匹配网址的结束字符 您可使用 $字符指定与网址的结束字符进行匹配。 例如,要拦截以 结尾的网址,可使用下列条目: User-agent: Googlebot Disallow: /*$ 您可将此模式匹配与 Allow 指令配合使用。 例如,如果 ? 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。 但是,以 ? 结尾的网址可能是您要包含的网页版本。 在此情况下,可对 文件进行如下设置: User-agent: * Allow: /*?$ Disallow: /*? Disallow: / *? 一行将拦截包含 ? 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (?),而后又是任意字符串的网址)。 Allow: /*?$ 一行将允许包含任何以 ? 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (?),问号之后没有任何字符的网址)。 Robots协议举例 禁止所有机器人访问User-agent:*Disallow:/ 允许所有机器人访问User-agent:*Disallow: 禁止特定机器人访问User-agent:BadBotDisallow:/ 允许特定机器人访问User-agent:GoodBotDisallow: 禁止访问特定目录User-agent:*Disallow:/images/ 仅允许访问特定目录User-agent:*Allow:/images/Disallow:/ 禁止访问特定文件User-agent:*Disallow:/*$ 仅允许访问特定文件User-agent:*Allow:/*$Disallow:/ 尽管已经存在很多年了,但是各大搜索引擎对它的解读都有细微差别。 Google与网络都分别在自己的站长工具中提供了robots工具。 如果您编写了文件,建议您在这两个工具中都进行测试,因为这两者的解析实现确实有细微差别。 更多青晟网络资讯请登录官方网站:或者
这几行文字我看不懂尤其是关于robots 那句到底是什么意思 有什么做用?
其中的属性说明如下: 设定为all:文件将被检索,且页面上的链接可以被查询; 设定为none:文件将不被检索,且页面上的链接不可以被查询; 设定为index:文件将被检索; 设定为follow:页面上的链接可以被查询; 设定为noindex:文件将不被检索,但页面上的链接可以被查询; 设定为nofollow:文件将不被检索,页面上的链接可以被查询。 ----------------------------------- 我们知道,搜索引擎都有自己的“搜索机器人”(ROBOTS),并通过这些ROBOTS在网络上沿着网页上的链接(一般是HTTP和src链接)不断抓取资料建立自己的数据库。 对于网站管理者和内容提供者来说,有时候会有一些站点内容,不希望被ROBOTS抓取而公开。 为了解决这个问题,ROBOTS开发界提供了两个办法:一个是,另一个是The Robots META标签。
外链关键词: 免试专升本具体流程 金针菇腌制方法 大专学历程女生 人体摄影网 上海近期天气预报15天 文水个人急售二手房 凯美瑞和迈腾哪个好 南京至石家庄飞机票本文地址: https://www.q16k.com/article/388db084b0bf1e42c5b2.html

爱集码源码是一个优质的资源分享平台,提供各种PHP源码、网站源码、模板插件、软件工具、网络教程等站长资源,为中国站长提供一个优质高效的源码下载站。

88软件园免费提供好玩的手机游戏下载、手机软件下载、手机网游下载等信息,提供安卓应用等各个平台的好玩的应用下载。

李俊伟博客创立于2021年,我们致力于分享生活故事、随笔写作、网络创业等文章,为志同道合的网络创业者提供知识获取及交流的平台。

时尚头条网LADYMAX.cn是国内影响力时尚媒体,提供每日时尚新闻,专注报道奢侈品动态和时尚产业
水星音乐
该站点未添加描述description...

该站点未添加描述description...
电脑技巧,电脑知识,电脑操作,电脑基础,电脑教程,网站赚钱,网站推广,软件故障,硬件故障,网址大全,windows技巧,word技巧,excel技巧,powerpoint技巧,photoshop技巧,dreamweaver技巧,flash技巧,fireworks技巧
该站点未添加描述description...
该站点未添加描述description...
该站点未添加描述description...
该站点未添加描述description...
该站点未添加描述description...
Shunho Optics Group
说说网(www.taiks.com)提供各种人生感悟的说说美文句子。有说说短句、说说美文、说说故事、说说作文及说说诗歌等,带给您最深的感动。
向日葵视频版本下载 迅雷下载是快手跟抖音一模一样不收费的的免费软件,免登录、不付费、无注册,所有的复杂程序都被删除。

2024最新房贷计算器,超过100万人使用地房贷计算器,更新快又好用地房贷计算器。
该站点未添加描述description...


随着白天博客的发展与完善,在网站领域方面博客内容将不再仅限于SEO优化类相关知识,为了让博客更完善,白天博客的导航栏会慢慢增加更多功能性的内容,但总有一些栏目或导航链接是不需要参与搜索引擎排名,为了尽量让蜘蛛抓取一些有用的页面,因此白天打算在这些不需要参与排名的导航链接上添加属性。那么怎么添加呢?为Wordpress网站导航栏添加no...

在接手一个网站时,无论做什么诊断分析,都少不了检查robots文件,为什么有的网站天天发文章却未见收录,很有可能是因为被robots文件里的规则屏蔽搜索引擎抓取所导致的。那么什么是robots文件,对于一个网站它的作用的什么?本文白天为你详细介绍robots文件并教你robots文件正确的写法。图1robots文件一、robots文件...

有时候有些页面访问消耗性能比较高不想让搜索引擎抓取,可以在根目录下放robots.txt文件屏蔽搜索引擎或者设置搜索引擎可以抓取文件范围以及规则。Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(RobotsExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面...
相信做过网站优化的朋友都听过robots文件和,但是大家真正清楚它们的作用与用途吗?不瞒大家说,白天也经常犯迷糊,好像他们的作用是一样的。但这真的只是好像,它们的不同点反而很多。那么本篇文章白天就来给大家讲讲经过多次研究后,说说白天对robots与nofollow的理解。首先先从它们的定义开始:robots在网站里通常是指robots...

考虑到一些主题没有自带这个功能,下面白天就来给大家分享一个既能让WordPress网站内容页的导出链接自动添加nofollow属性而且还以新窗口打开,以此尽可能减少自己网站的权重流失以及用户流失。如何使wordpress的标签自动变为网站文章的内链方法一、使用插件SEOSmartLinks插件:介绍:SEOSmartLinks可以通过...
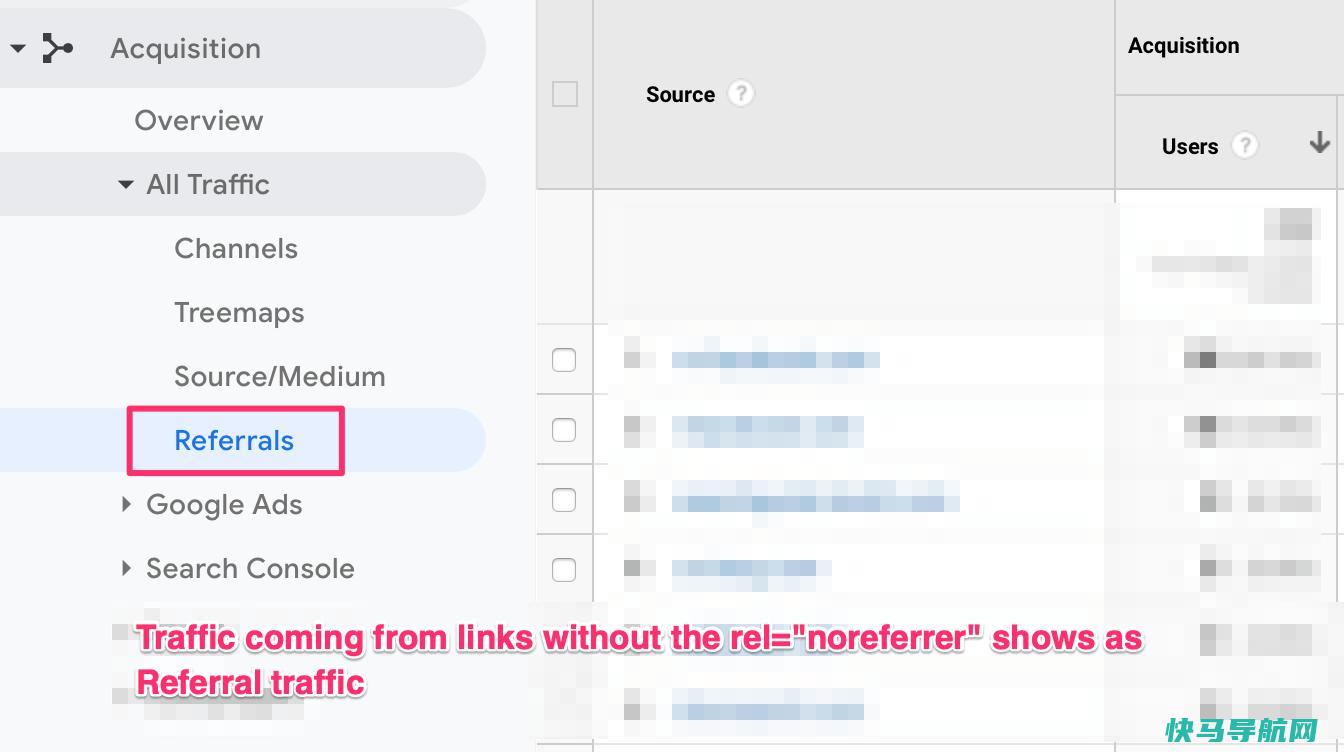
“noreferrernoopener”是HTML中a标签的一种属性,在本篇文章中,小编将给大家解释noreferrer和noopener标签之间的区别,它们与nofollow标签的区别,以及使用它们时对SEO的影响。什么是rel=”noreferrer”?通过在a标签添加noreferrer属性,则意味着在GoogleAnalyti...

在接手一个网站时,无论做什么诊断剖析,都少不了审核robots文件,为什么有的网站天天发文章却未见收录,很有或许是由于被robots文件里的规则屏蔽搜查引擎抓取所造成的。那么什么是robots文件,关于一个网站它的作用的什么?本文白昼为你详细引见robots文件并教你robots文件正确的写法。图1robots文件一、robots文件...

谈到谷歌SEO的外链建设工作,许多人面临一些头痛的问题。例如,很难找到与内容相关性高但适合做外链的网站,而找到内容相关的网站时又发现它们的域名权重比较低。而在权重高的网站上发布的外链大多都设置了nofollow等限制,这些情况使得外链建设工作变得被动。针对上述情况,今天我们要介绍的是GuestPostTracker这个外链建设工具。一...

我们都知道网站想要有排名必须要先增加百度收录,同时标题要包含指数关键词,这样才可以提高第三方平台的百度权重值,我们在交换友链时收录数量也是一个交换的标准,比如你的网站收录是一万,我想你不会跟收录只有100的网站做链接。新网站想要增加百度收录除了内容要优质外,还要通过外部链接引蜘蛛到访,并且网站的robots文件没有拒绝蜘蛛爬行,日更文...

球迷们习惯了如果他们想看比赛就换频道。NFL急切地削减了向CBS、福克斯和NBC等主要电视网出售产品的时间表。随着流媒体视频服务比以往任何时候都更受欢迎,这创造了更多的在线平台,努力参与到这场格斗中来。没有几家公司的网络业务比亚马逊更强大。PrimeVideo拥有未来十年周四晚间足球比赛的独家转播权。PrimeVideo的价格为8.9...

地球上有一个巨大的电子废品问题。我们人类丢弃了如此之多的手机、电脑、电池和其他电子废品,以至于仅仅一年,我们就产生了超过1360亿磅(620亿公斤)的电子废品。更糟糕的是,这些废品中只有一小部分得到了适当的收集和回收,因此大部分最终被送进了废品填埋场。淘汰旧电子产品,无论是因为它们不再擦出喜悦的火花,还是真的开始擦出火花,都是一项必须...

大家好,今天来为大家分享着急是卖家还是买家的一些知识点,和着急用怎么催卖家发货的问题解析,大家要是都明白,那么可以忽略,如果不太清楚的话可以看看本篇文章,相信很大概率可以解决您的问题,接下来我们就一起来看看吧!本文目录一、淘宝介入判决支持卖家,为什么显示退货退款,到底是退给卖家还是买家非质量问题退货,买家只要承担自主退回运费。你只要承...

说明:接口缺省都加入了VLAN1,因此加入Eth-Trunk前建议先将接口从VLAN1中退出或将接口Shutdown,避免出现广播风暴。配置系统优先级,确定主动端,按照主动端设备的接口选择活动接口。交换机的端口聚合配置链路聚合将交换机上的多个端口在物理上连接起来,在逻辑上捆绑在一起。1、形成较大宽带的端口。2、实现负载分担,并提供冗余...
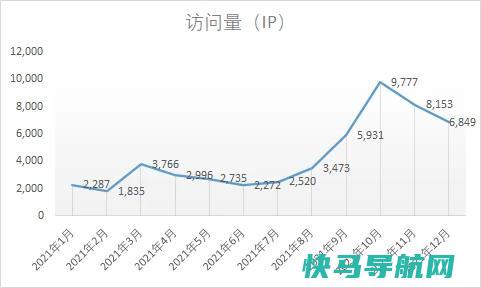
难得准时的给即将过去的2021年做一次总结。这一年依旧过的很快,此时做总结,一片茫然,2021年我到底做了啥…这一年,自己的博客算是废了,基本没更新什么文章,计划是365篇,但实际只更新了35篇。相较于之前的文章,今年的文章大都文属于灌水,质量差、而且方向有些偏了,网站跳出率更高了。流量方面,本以为在这样的情况下(文章更新少、质量差)...