 用户中心
用户中心什么是搜索引擎蜘蛛|基本工作原理是什么
搜索引擎蜘蛛并不是我们日常见到的蜘蛛,它只是搜索引擎指派出的一个有调度机制的抓取程序,用于抓取互联网中的网页,不同的搜索引擎Spider也会有不同的分类,但大部分的Spider都是解决相同的问题,有着相同的工作原理。今天我们详细讲下什么是搜索引擎蜘蛛?
一、什么是搜索引擎(SearchEngine)
搜索引擎是指根据一定的策略、运用特定的电脑程序搜集互联网上的信息,在对信息进行组织和处理后,为用户提供检索服务的系统。全球网络上的信息浩瀚万千,而且毫无秩序,所有的信息象汪洋上的一个个小岛,网页链接是这些小岛之间纵横交错的桥梁,而搜索引擎,则为用户绘制一幅一目瞭然的信息地图,供用户随时查阅。从使用者的角度看,搜索引擎提供一个包含搜索框的页面,在搜索框输入词语,通过浏览器提交给搜索引擎后,搜索引擎就会返回跟用户输入的内容相关的信息列表。以下是世界上一些最受欢迎的搜索引擎:
二、什么是搜索引擎蜘蛛
搜索引擎使用他们开发的机器人工作,称为蜘蛛或网络爬虫,每天抓取数十亿个页面。这些机器人跟踪页面之间的链接,在此过程中将新内容添加到搜索引擎的索引中。每次我们使用搜索引擎时,它都会使用一种算法使用其索引中的信息来查找和排名结果。深入分析网站的SEO表现的时候,一般我们会考虑蜘蛛搜索引擎的抓取质量,而其中能够帮我们优化网站可能会涉及到以下的几个蜘蛛抓取相关的概念:
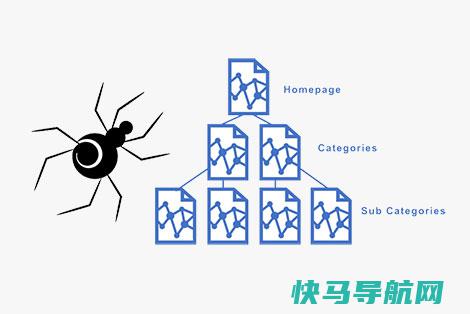
- 爬取率:既定时间内网站被蜘蛛获取的页面数量。
- 爬取频率:搜索引擎多久对网站或单个网页发起一次新的爬行。
- 爬取深度:一个蜘蛛从开始位置可以点击到多深。
- 爬取饱和度:唯一页面被获取的数量。
- 爬取优先:那些页面最常作为蜘蛛的入口。
- 爬取冗余度:网站一般被多少蜘蛛同时爬取。
- 爬取mapping:蜘蛛爬取路径还原。

简单来说,搜索引擎蜘蛛是搜索引擎自身的一个程序,它的作用是对网站的网页进行访问,抓取网页的文字、图片等信息,建立一个数据库,反馈给搜索引擎,当用户搜索的时候,蜘蛛搜索引擎就会把收集到的信息过滤,通过复杂的排序算法将它认为对用户最有用的信息呈现出来。
三、搜索引擎的组成
搜索引擎一般由搜索器、索引器、检索器和用户介面四个部分组成:
- 搜索器:其功能是在互联网中爬行,发现和搜集信息。
- 索引器:其功能是理解搜索器所搜索到的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。
- 检索器:其功能是根据用户的查询在索引库中快速检索文档,进行相关度评价,对将要输出的结果排序,并能按用户的查询需求合理反馈信息。
- 用户介面:其作用是接纳用户查询、显示查询结果、提供个性化查询。

四、搜索引擎的工作原理
搜索引擎的信息搜集基本都是自动的。搜索引擎利用称为网络蜘蛛的自动搜索机器人程序来发现每一个网页上的超链接。机器人程序根据网页链到其他页面中的超链接,就象日常生活中所说的一传十,十传百……一样,从少数几个网页开始,连到页面上所有到其他网页的链接。理论上,如果网页上有源代码显示正常的超链接,机器人便可以爬取绝大部分网页。搜索引擎整理信息的过程称为建立索引。搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。这样,搜索引擎根本不用重新翻查它所有保存的信息而迅速找到所要的资料。想象一下,如果信息是不按任何规则地随意堆放在搜索引擎的资料库中,那么它每次找资料都得把整个资料库完全翻查一遍,如此一来再快的电脑系统也承受不了。用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回资料。搜索引擎每时每刻都要接到来自大量用户的几乎是同时发出的查询,它按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料,并返回给用户。目前,搜索引擎返回主要是以网页链接的形式提供的,这样通过这些链接,用户便能到达含有自己所需资料的网页。通常搜索引擎会在这些链接下提供一小段来自这些网页的
剖析搜索引擎蜘蛛工作原理是神马 ??
设定通常是以时间或是数量为依据,可以以链接的层数来限制网络蜘蛛的爬取
什么是搜索引擎蜘蛛?
搜搜引擎蜘蛛是一个自动抓取互联网上网页内容的程序,每个搜索引擎都有自己的蜘蛛。 搜索引擎蜘蛛也叫搜索引擎爬虫、搜索引擎robot。 国内各大搜索引擎蜘蛛名称: 网络:网络spider 谷歌:googlebot 网络:sogou spider 搜搜:Sosospider 360搜索:360Spider 有道:YodaoBot 雅虎:Yahoo Slurp 必应:msnbot Msn:msnbot 以上是常见的搜索引擎蜘蛛(爬虫),如果你的网站不想让让某些蜘蛛抓取,那么可以通过robots.txt来限制爬虫的抓取。
百度等搜索引擎(网络蜘蛛)抓取页面的原理
搜索引擎基本工作原理了解搜索引擎的工作原理对我们日常搜索应用和网站提交推广都会有很大帮助。........................................................................................■ 全文搜索引擎在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,出现的位置/频次,链接质量等——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。........................................................................................■ 目录索引与全文搜索引擎相比,目录索引有许多不同之处。首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。用户提交网站后,目录编辑人员会亲自浏览你的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,决定是否接纳你的网站。其次,搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功。而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。尤其象 Yahoo!这样的超级索引,登录更是困难。(由于登录Yahoo!的难度最大,而它又是商家网络营销必争之地,所以我们会在后面用专门的篇幅介绍登录 Yahoo雅虎的技巧)此外,在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。最后,搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。更有甚者,如果工作人员认为你提交网站的目录、网站信息不合适,他可以随时对其进行调整,当然事先是不会和你商量的。目录索引,顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟搜索引擎一样,也是根据信息关联程度排列网站,只不过其中人为因素要多一些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先后顺序决定(也有例外)。目前,搜索引擎与目录索引有相互融合渗透的趋势。原来一些纯粹的全文搜索引擎现在也提供目录搜索,如Google就借用Open Directory目录提供分类查询。而象 Yahoo! 这些老牌目录索引则通过与Google等搜索引擎合作扩大搜索范围(注)。在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如国内搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。
什么是搜索引擎
搜索引擎指能够自动从互联网上搜集信息,经过整理以后,提供给用户进行查阅的系统。
搜索引擎的工作原理大致如下:
搜集信息:由于互联网上的数据量非常庞大,搜索引擎的信息搜集基本都是自动完成的。搜索引擎利用被称为网络蜘蛛的自动搜索程序来连上每一个网页上的超链接。从少数几个网页开始,连到数据库上所有到其他网页的链接。
整理信息:搜索引擎整理信息的过程称为“建立索引”。搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。这样,搜索引擎不用重新翻查它所有保存的信息就能迅速找到所要的资料。
接受查询:用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回信息。搜索引擎能够按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料,并返回给用户。目前,搜索引擎返回主要是以网页链接的形式提供的,这些通过这些链接,用户便能到达所需的网页。通常搜索引擎会在这些链接下提供一小段来自这些网页的摘要信息以帮助用户判断此网页是否含有自己需要的内容。
>> 百度搜索引擎蜘蛛的工作原理是什么?
搜索引擎蜘蛛名称根据搜索引擎都不同。那它的原理是由一个启始链接开始抓取网页内容,同时也采集网页上的链接,并将这些链接作为它下一步抓取的链接地址,如此循环,直到达到某个停止条件后才会停止。停止条件的设定通常是以时间或是数量为依据,可以通过链接的层数来限制网络蜘蛛的爬取。同时页面信息的重要性为客观因素决定了蜘蛛对该网站页面的检索。站长工具中的搜索引擎蜘蛛模拟器其实它就是这个原理。基于这蜘蛛工作原理,站长都会不自然的增加页面关键词出现次数,虽然对密度产生量的变化,但对蜘蛛而言并没达到一定质的变化。这在搜索引擎优化过程中应该要避免的。
互联网蜘蛛
网络蜘蛛基本原理 网络蜘蛛即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。 对于搜索引擎来说,要抓取互联网上所有的网页几乎是不可能的,从目前公布的数据来看,容量最大的搜索引擎也不过是抓取了整个网页数量的百分之四十左右。这其中的原因一方面是抓取技术的瓶颈,无法遍历所有的网页,有许多网页无法从其它网页的链接中找到;另一个原因是存储技术和处理技术的问题,如果按照每个页面的平均大小为20K计算(包含图片),100亿网页的容量是100×2000G字节,即使能够存储,下载也存在问题(按照一台机器每秒下载20K计算,需要340台机器不停的。。。。。。。。。。。。。
外链关键词: 中国最好喝的白酒 全文专业率 中央财大最好的专业 世界第一初恋在线看 教师专业化与专业发展 安徽省合肥市巢湖市天气预报 梦见屋倒 日本机床世界第一本文地址: https://www.q16k.com/article/8891ed8819546af087a5.html

网站图片下载神器,网站原图批量下载,支持微博、花瓣、豆瓣等国内外几十个网站原图一键下载

该站点未添加描述description...
该站点未添加描述description...

小学生自学网为小学生的学习提供丰富的学习资源,满足孩子们自学的需要,小学生学习资源网,良犬课件,良犬软件

该站点未添加描述description...

海隆石油
该站点未添加描述description...

经济观察网是《经济观察报》社倾力制作的全新商业资讯平台,经济观察网冷静理智的报道风格,并糅合最新的网络技术,拥有专业的采编力量以及独家的新闻报道,为您提供及时、便捷、专业的信息服务。
Harrodser has participated in famous musical instrument exhibitions in Frankfurt, Germany, the United States, Beijing and Shanghai for many years. Harrodser has won the recognition of the Chinese people and the pursuit of the market with its excellent quality, good reputation and perfect after-sales. At present, Harrodser has more than 300 distributors in China. We have partners in the United States, Colombia, India, Iran, Singapore, Thailand, Vietnam and so on The piano for you, for now, for e
杜鹃花地栽养殖方法
凌空资源网致力于为广大用户提供优质的手机应用,游戏资源,游戏攻略、技术教程等资源,并为大家提供免费绿色安全的下载服务。
该站点未添加描述description...
该站点未添加描述description...
飞飞盘支持百度云搜索,可快速搜索百度网盘资源中的有效连接,自动识别无效的百度云网盘资源,每天更新海量资源。
毕达举办的一系列公益活动。
该站点未添加描述description...

叫卖录音网,一个专业做各种录音配音的网站,叫卖录音广告、叫卖广告录音找叫卖录音网
该站点未添加描述description...

搜索引擎蜘蛛并不是我们日常见到的蜘蛛,它只是搜索引擎指派出的一个有调度机制的抓取程序,用于抓取互联网中的网页,不同的搜索引擎Spider也会有不同的分类,但大部分的Spider都是解决相同的问题,有着相同的工作原理,今天我们详细讲下什么是搜索引擎蜘蛛,一、什么是搜索引擎,SearchEngine,搜索引擎是指根据一定的策略、运用特定的...。
这曾经是一句老生常谈,几乎成了老生常谈:如果你想玩游戏,就不要买Mac。苹果电脑用户有马拉松和神秘,但大量游戏从未移植到Mac上,而几乎每一款Mac独家游戏最终都在PC上找到了归宿。对于苹果粉丝来说,幸运的是,那些日子现在基本上已经过去了。虽然在Mac上玩游戏的体验仍然比PC游戏略有限,但现在只要有足够的耐心和毅力,你就可以在Mac上...

你会听到收到短信的声音,然后兴奋地查看手机。但这只是废品邮件发送者发送给你的废品消息,试图欺骗你点击链接、打开附件、拨打号码或安装恶意软件。Robotexts和废品邮件是一个令人不快的事实,就像机器人电话和废品邮件一样。它们可能不像废品邮件电话那样具有侵入性,因为你可以在很大程度上忽略它们,但这并不意味着它们是无害的。一些手机套餐可能...

您正在出售或捐赠旧iPhone、iPad或Android设备,并希望确保其他人无法访问您的个人信息。出于这个原因,你会想要在摆脱你的设备之前擦除你自己和你的数据的所有痕迹。通过执行出厂重置,您将擦除设备中的所有个人信息、应用程序和内容,这样新所有者就无法窥探您的小工具。一旦你迈出了这一步,你就可以安全地出售你的iPhone或Andro...

大家好,今天来为大家分享着急是卖家还是买家的一些知识点,和着急用怎么催卖家发货的问题解析,大家要是都明白,那么可以忽略,如果不太清楚的话可以看看本篇文章,相信很大概率可以解决您的问题,接下来我们就一起来看看吧!本文目录一、淘宝介入判决支持卖家,为什么显示退货退款,到底是退给卖家还是买家非质量问题退货,买家只要承担自主退回运费。你只要承...

经常听到有人说域名被墙了,什么是被墙呢?域名被墙会有哪些表现呢?本文白天就来详细给大家介绍一下域名被墙。什么是域名被墙“网站被墙”一般是因为国内防火墙(GFW)屏蔽了网站域名。广义上讲是指网站的域名或IP地址由于某些原因(如:网站存在敏感内容或非法内容)被屏蔽,使得网站在部分地区无法访问。特别是网站放在国外服务器或域名放在国外DNS上...