 用户中心
用户中心禁止百度蜘蛛 禁止谷哥蜘蛛等方法大全
有些时候我们会遇到这样的困难:我们原本不想被搜索引擎收录的网站后台地址却被搜索引擎“无情”的收录,这样只要在Google里输入一个“后台、管理site:www.soumore.com”,自己的后台地址就会显露无疑,因此网站安全性也无从谈起。遇到这样的情况时,我们如何阻止搜索引擎收录我们不想被收录的文件呢?

一般在这个时候,我们常用的办法有两个,一个是编辑robots.txt文件,另外一个是在不想被收录的页面头部放置META NAME="ROBOTS"标签。
所谓的robots.txt文件,是每一个搜索引擎到你的网站之后要寻找和访问的第一个文件,robots.txt是你对搜索引擎制定的一个如何索引你的网站的规则。通过这个文件,搜索引擎就可以知道在你的网站中,哪些文件是可以被索引的,哪些文件是被拒绝索引的。
在很多网站中,站长们都忽略了使用robots.txt文件。因为很多站长都认为,自己的网站没有什么秘密可言,而且自己也不太会使用robots.txt的语法,因此一旦写错了会带来更多的麻烦,还不如干脆不用。
其实这样的做法是不对的。在前面的文章中我们知道,如果一个网站有大量文件找不到的时候(404),搜索引擎就会降低网站的权重。而robots.txt作为蜘蛛访问网站的第一个文件,一旦搜索引擎要是找不到这个文件,也会在他的索引服务器上记录下一条404信息。
虽然在百度的帮助文件中,有这样的一句话“请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。”但是我个人还是认为建立robots.txt还是必须的,哪怕这个robots.txt文件是一个空白的文本文档都可以。因为我们的网站毕竟不是仅仅会被百度收录,同时也会被其他搜索引擎收录的,所以,上传一个robots.txt文件还是没有什么坏处的。
如何写一个合理的robots.txt文件?
首先我们需要了解robots.txt文件的一些基本语法。
|
语法作用 |
写法 |
|
允许所有搜索引擎访问网站的所有部分 或者建立一个空白的文本文档,命名为robots.txt |
User-agent: * Disallow: 或者 User-agent: * Allow: / |
|
禁止所有搜索引擎访问网站的所有部分 |
User-agent: * Disallow: / |
|
禁止百度索引你的网站 |
User-agent: Baiduspider Disallow: / |
|
禁止Google索引你的网站 |
User-agent: Googlebot Disallow: / |
|
禁止除Google外的一切搜索引擎索引你的网站 |
User-agent: Googlebot Disallow: User-agent: * Disallow: / |
|
禁止除百度外的一切搜索引擎索引你的网站 |
User-agent: Baiduspider Disallow: User-agent: * Disallow: / |
|
禁止蜘蛛访问某个目录 (例如禁止admin\css\images被索引) |
User-agent: * Disallow: /css/ Disallow: /admin/ Disallow: /images/ |
|
允许访问某个目录中的某些特定网址 |
User-agent: * Allow: /css/my Allow: /admin/html Allow: /images/index Disallow: /css/ Disallow: /admin/ Disallow: /images/ |
|
使用“*”,限制访问某个后缀的域名 例如索引访问admin目录下所有ASP的文件 |
User-agent: * Disallow: /admin/*.htm |
|
使用“$”仅允许访问某目录下某个后缀的文件 |
User-agent: * Allow: .asp$ Disallow: / |
|
禁止索引网站中所有的动态页面 (这里限制的是有“?”的域名,例如index.asp?id=1) |
User-agent: * Disallow: /*?* |

有些时候,我们为了节省服务器资源,需要禁止各类搜索引擎来索引我们网站上的图片,这里的办法除了使用“Disallow: /images/”这样的直接屏蔽文件夹的方式之外,还可以采取直接屏蔽图片后缀名的方式。具体办法如下。
|
语法作用 |
写法 |
|
禁止Google搜索引擎抓取你网站上的所有图片 (如果你的网站使用其他后缀的图片名称,在这里也可以直接添加) |
User-agent: Googlebot Disallow: .jpg$ Disallow: .jpeg$ Disallow: .gif$ Disallow: .png$ Disallow: .bmp$ |
|
禁止百度搜索引擎抓取你网站上的所有图片 |
User-agent: Baiduspider Disallow: .jpg$ Disallow: .jpeg$ Disallow: .gif$ Disallow: .png$ Disallow: .bmp$ |
|
除了百度之外和Google之外,禁止其他搜索引擎抓取你网站的图片 (注意,在这里为了让各位看的更明白,因此使用一个比较笨的办法——对于单个搜索引擎单独定义。) |
User-agent: Baiduspider Allow: .jpeg$ Allow: .gif$ Allow: .png$ Allow: .bmp$ User-agent: Googlebot Allow: .jpeg$ Allow: .gif$ Allow: .png$ Allow: .bmp$ User-agent: * Disallow: .jpg$ Disallow: .jpeg$ Disallow: .gif$ Disallow: .png$ Disallow: .bmp$ |
|
仅仅允许百度抓取网站上的“JPG”格式文件 (其他搜索引擎的办法也和这个一样,只是修改一下搜索引擎的蜘蛛名称即可) |
User-agent: Baiduspider Allow: .jpg$ Disallow: .jpeg$ Disallow: .gif$ Disallow: .png$ Disallow: .bmp$ |
|
仅仅禁止百度抓取网站上的“JPG”格式文件 |
User-agent: Baiduspider Disallow: .jpg$ |
在了解了以上这些基础的语法之后,对于robots.txt的写法各位已经有了一个大概的概念了,不过在学习写作robots.txt文件时,我们还必须要了解一些大型搜索引擎的蜘蛛名称,这样可以便于我们写做robots.txt文件。
|
蜘蛛名称 |
作用 |
|
Googlebot |
Google对一般网页的索引蜘蛛 |
|
Googlebot-Mobile |
Google对于移动设备,如手机网页的索引蜘蛛 |
|
Googlebot-Image |
Google专门用来抓取图片的蜘蛛 |
|
Mediapartners-Google |
这是Google专门为放置了Google Adsense广告联盟代码的网站使用的专用蜘蛛,只有网站放置了Google Adsense代码的情况下,Google才会使用这个蜘蛛。这个蜘蛛的作用是专门抓取Adsense广告内容 |
|
Adsbot-Google |
这是Google专门为Google Adwords客户设计的蜘蛛,如果你使用了Google的Adwords服务,那么这个蜘蛛就会派出这个蜘蛛来衡量放置了你广告的网站的质量。 |
|
百度蜘蛛Baiduspider |
百度的综合索引蜘蛛 |
|
雅虎蜘蛛:Yahoo! Slurp |
雅虎的综合索引蜘蛛 |
|
雅虎搜索引擎广告蜘蛛Yahoo!-AdCrawler |
雅虎专门为Yahoo!搜索引擎广告开发的专用蜘蛛 |
|
网易有道蜘蛛YodaoBot |
网易有道搜索引擎综合索引蜘蛛 |
|
腾讯SOSO蜘蛛Sosospider |
腾讯SOSO综合索引蜘蛛 |
|
搜狗蜘蛛sogou spider |
搜狗综合索引蜘蛛 |
|
MSNBot |
Live综合索引蜘蛛 |
注意:以上蜘蛛名称请按照图表区分大小写
在上面这些搜索引擎蜘蛛中,我们最常用的就是Googlebot和Baiduspider,因此对这两个蜘蛛的用法要特别注意。
以上的robots.txt文件可以帮助我们对于搜索引擎的访问做一个限制,这里需要注意的有几个方面。
1、 robots.txt文件必须处于网站根目录下,而且必须命名为robots.txt
2、 robots.txt文件的文件名全部是小写字母,没有大写字母。
3、 如果对于robots.txt文件的写法把握不准,那么可以直接放一个空的文本文档,命名为robots.txt即可。
好了,以上我们介绍了robots.txt的写法。这时候有一个问题,有些时候我们会遇到一些实际的特殊情况,那么遇到特殊情况我们应当怎样处理呢?一下就对限制搜索引擎的原标签(META)做一个介绍。
第一种情况:限制网页快照
很多搜索引擎都提供一个网页快照的功能。但是网页快照功能却有很多的弊端,例如事实内容在网页快照中更新不及时、索引网页快照浪费大量的服务器资源等。因此,我们有些时候可能并不需要搜索引擎来索引我们某个页面的网页快照。
解决这样问题的办法很简单,只需要在你的网页元标记中(和之间)放置如下的一段代码。
以上的一段代码限制了所有的搜索引擎建立你的网页快照。如果我们需要仅仅限制一个搜索引擎建立快照的话,就可以像如下这样去写
需要注意的是,这样的标记仅仅是禁止搜索引擎为你的网站建立快照,如果你要禁止搜索引擎索引你的这个页面的话,请参照后面的办法。
第二种情况:禁止搜索引擎抓取本页面。
在SEO中,禁止搜索引擎抓取本页面或者是允许搜索引擎抓取本页面是经常会用到的。因此我们需要对这一部分重点做一次讨论。
为了让搜索引擎禁止抓取本页面,我们一般的做法是在页面的元标记中加入如下的代码:
在这里,META NAME="ROBOTS"是泛指所有的搜索引擎的,在这里我们也可以特指某个搜索引擎,例如META NAME="Googlebot"、META NAME="Baiduspide"等。content部分有四个命令:index、noindex、follow、nofollow,命令间以英文的“,”分隔。
INDEX命令:告诉搜索引擎抓取这个页面
FOLLOW命令:告诉搜索引擎可以从这个页面上找到链接,然后继续访问抓取下去。
NOINDEX命令:告诉搜索引擎不允许抓取这个页面
NOFOLLOW命令:告诉搜索引擎不允许从此页找到链接、拒绝其继续访问。
根据以上的命令,我们就有了一下的四种组合
:可以抓取本页,而且可以顺着本页继续索引别的链接
:不许抓取本页,但是可以顺着本页抓取索引别的链接
:可以抓取本页,但是不许顺着本页抓取索引别的链接
:不许抓取本页,也不许顺着本页抓取索引别的链接。
这里需要注意的是,不可把两个对立的反义词写到一起,例如
或者直接同时写上两句
这里有一个简便的写法,如果是
的形式的话,可以写成:
如果是
的形式的话,可以写成:
当然,我们也可以把禁止建立快照和对于搜索引擎的命令写到一个命令元标记中。从上面的文章中我们得知,禁止建立网页快照的命令是noarchive,那么我们就可以写成如下的形式:
如果是对于单独的某个搜索引擎不允许建立快照,例如百度,我们就可以写成:
如果在元标记中不屑关于蜘蛛的命令,那么默认的命令即为如下
因此,如果我们对于这一部分把握不准的话,可以直接写上上面的这一行命令,或者是直接留空。
在SEO中,对于蜘蛛的控制是非常重要的一部分内容,所以希望各位看官准确把握这部分的内容。
外链关键词: 水煮白菜减肥法 朝鲜美女 世界第一美女 帅哥美女图片 广东mpa专业排名 梦见蝴蝶飞走了 深度水解奶粉有哪些 北京干部教育网官网本文地址: https://www.q16k.com/article/8ea0545a968c6009c0b2.html

1ya1资源网主要收集各类精品源码资源,包含WordPress主题插件、CMS模板源码、网站源码、游戏源码、APP源码、编程开发视频教程等 ,希望小主多多支持!

该站点未添加描述description...
该站点未添加描述description...
该站点未添加描述description...
尚游在线|为网络游戏玩家提供用户体验至上的网络游戏产品服务。
该站点未添加描述description...
该站点未添加描述description...
该站点未添加描述description...
Flutter 是 Google 开源的 UI 工具包,帮助开发者通过一套代码库高效构建多平台精美应用。本站提供 Flutter 开发资源索引,包括镜像、中文文档、问答、教程等。
中小企业营销推广中心是国内最完善移动网站及移动互联网技术解决方案。
该站点未添加描述description...
衢州新闻网

刀贱贱博客是国内较早的一家免费资源分享网站,提供优质的资源,用心打造全面的资源网平台,让我们的生活更加精彩!

本页提供其他特种电源最新产品及供应商信息

匹克会员俱乐部!中国篮球第一品牌
印刷小说阅读网是广大书友最值得收藏的网络小说阅读网,网站收录了当前最火热的网络小说,免费提供高质量的小说最新章节,是广大网络小说爱好者必备的小说阅读网。

全知百科是一个百科知识在线分享平台,包含最新热门关键词、热点话题、热点事件、网络话题和是什么梗,在线分享各类知识、经验和观点,我们的目标是只要是您的需要,我们全都知道。


宝塔Linux面板7.7.0开心版分享可通过面板上:“修复”进行升级到最新版或者“Linux面板7.7.0升级专业版命令”升级到最新版问:为什么企业版没永久?答:因为官方就没有永久呀,只有专业版有!本次主要更新内容:如果还有问题,欢迎提出,如果出现插件更新,点击更新还是提示更新的欢迎反馈!注意:请安装了开心版7.6.0的用户,面板提示...

如图一所示,为了保证网络的可靠性,用户侧网络采用双上行方式组网。用户希望能够破除网络环路,实现主备链路冗余备份和快速收敛。...

快速入门:用Alist打造终极看片神器,改变你的观影体验Alist是一个轻量级、跨平台的文件浏览和分享服务,支持将多种云存储和本地存储资源集中管理和访问,提供了一个简洁且高效的方式来整理和共享文件。Alist支持挂载国内常见网盘,如:阿里云盘/夸克网盘/百度网盘等,非常适合NAS用户或大带宽用户安装使用。通过Alist挂载网盘后,可以...
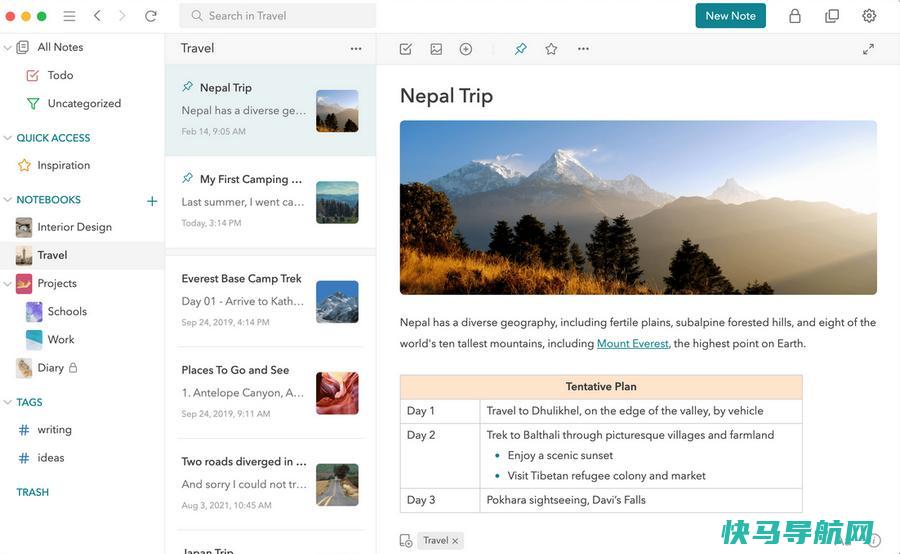
简洁而强大:UpNote多平台笔记应用入门指南不知道大家是否也有过像xiaoz一样的经历:尝试了无数笔记应用,却鲜少找到真正令人满意的,直到我发现了UpNote。这款应用因其简洁而强大的功能而受到推崇。它不仅拥有用户友好的界面和直观的操作流程,而且还是一款简单纯粹的笔记工具,真正做到了既美观又实用。关于UpNote虽然UpNote可能...

精选:NAS用户必装的十款软件,让你的NAS发挥极致(下篇)欢迎回到《精选:NAS用户必装的十款软件》系列文章的下篇!我是xiaoz。今天,我们将探索剩余的五款NAS软件,为你的NAS系统添砖加瓦。如果你错过了我们的上篇推荐,不要担心,你可以通过这个链接回顾:https://blog.xiaoz.org/archives/20490。...
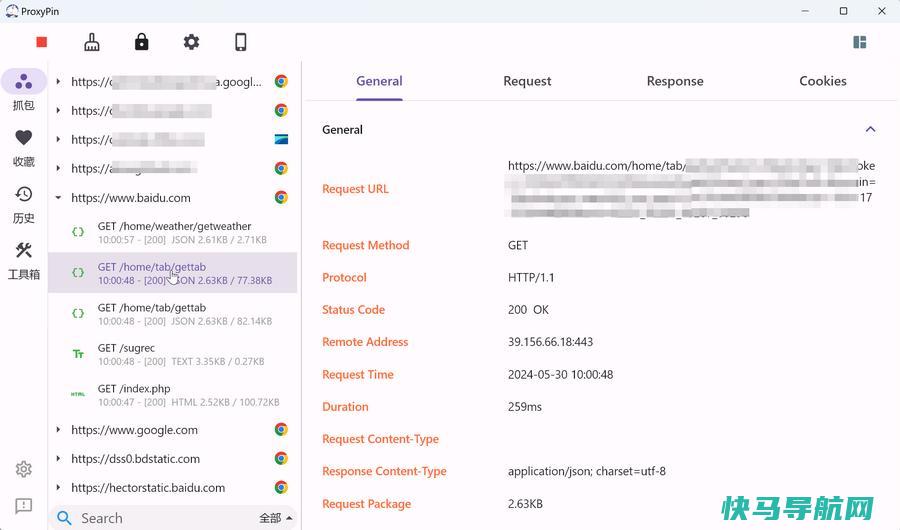
探索ProxyPin:开源免费的全平台HTTP抓包工具ProxyPin是一款开源抓包工具,它支持多种操作系统包括Windows、Mac、Android、IOS和Linux。该工具使用Flutter开发,界面美观易用。它使用户能够拦截、检查和重写HTTP(S)流量,非常适合开发人员或运维人员使用。ProxyPin特性安装ProxyPin...
探索星空组网:无公网IP的NAS用户,也能享受顺畅的网络连接体验最近群里的小伙伴向xiaoz推荐了一款名为星空组网的组网工具。经过安装和体验,我发现它非常适合没有公网IP的NAS用户。对此有需求的朋友们可以尝试一下。本文将详细介绍星空组网的基本用法。关于星空组网星空组网是一款采用前沿云虚拟局域网和SD-WAN智能组网技术的创新网络连接...

长桥证券新加坡/香港简易开户指南长桥证券是一家具有国际牌照的券商,持有香港、新加坡、新西兰、美国等地的多张牌照,提供了高标准的安全保障。长桥证券目前推出的港股和美股终生免佣交易活动特别适合长期投资美股的投资者,因为这可以显著降低交易成本。过去,开设长桥香港账户需要香港银行卡和存量证明,对没有香港银行卡的人来说较为不便。最近,长桥在香港...

小众但好用的AppleTV:开箱、配置、价格及必装软件推荐4条评论最近在拜访朋友家时,我被他的AppleTV深深吸引,经过一番尝试,我被它的性能和用户体验所折服,这激起了我购买的欲望。于是通过淘宝下单,购买了自己的AppleTV。在这篇文章中,我将分享我的开箱体验、购买价格,以及我个人推荐的一些必装软件。希望能为同样感兴趣的你提供有用...

成了!将小爱音箱接入ChatGPT1条评论xiaoz在一个朋友推荐下了解到这个项目,可以将家里的小爱音箱接入ChatGPT、ChatGLM等大模型,从而让小爱音箱变得更加智能。目前xiaoz已成功将家里的小米AI音箱一代接入到ChatGPT,大家可以通过下方的B站链接查看效果,如果有用,别忘记一键三联哦。开始之前此教程略微复杂,不适合...
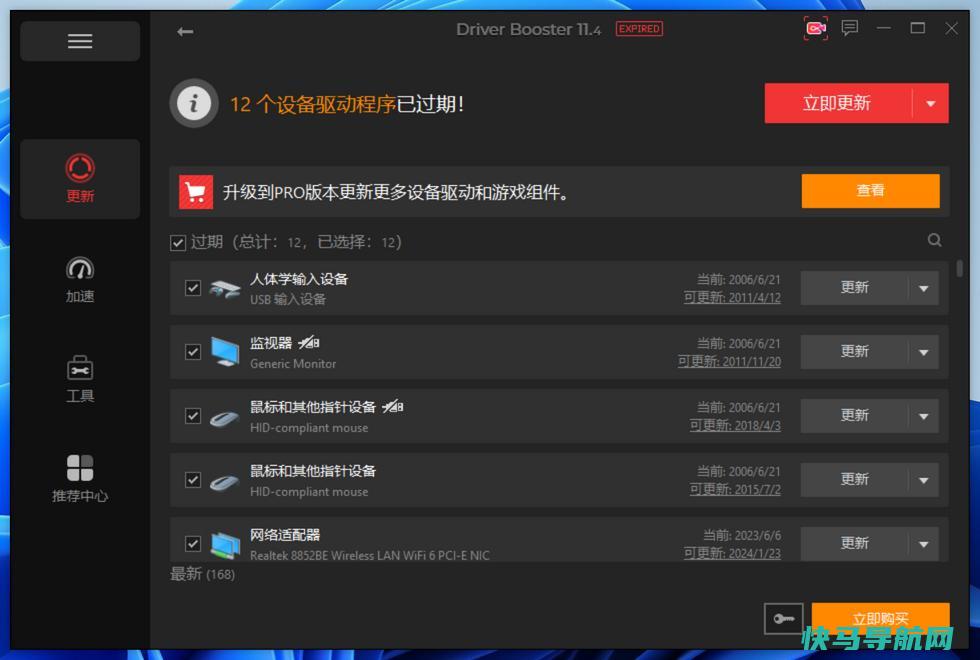
驱动管理新选择:借助DriverBooster解决驱动疑难杂症DriverBooster是一款为Windows用户设计的强大驱动更新工具,能自动检测并更新过时的驱动程序。它支持超过650万种设备驱动,能快速解决各种驱动相关的问题,从而提高系统的稳定性和性能。前言最近,xiaoz在尝试使用蓝牙鼠标时遇到了电脑无法识别设备的问题。怀疑是驱...

如何使用Proxifier实现应用级代理:一步步教程Proxifier是一款强大的网络工具,它允许用户为每个独立的应用程序设置专属的代理服务器,并且支持WindowsUWP应用。这篇文章,博主将一步步展示如何使用Proxifier实现应用级代理,无论您是希望提升网络访问速度,还是需要特别配置的代理需求,都能找到解决方案。使用场景不知道...
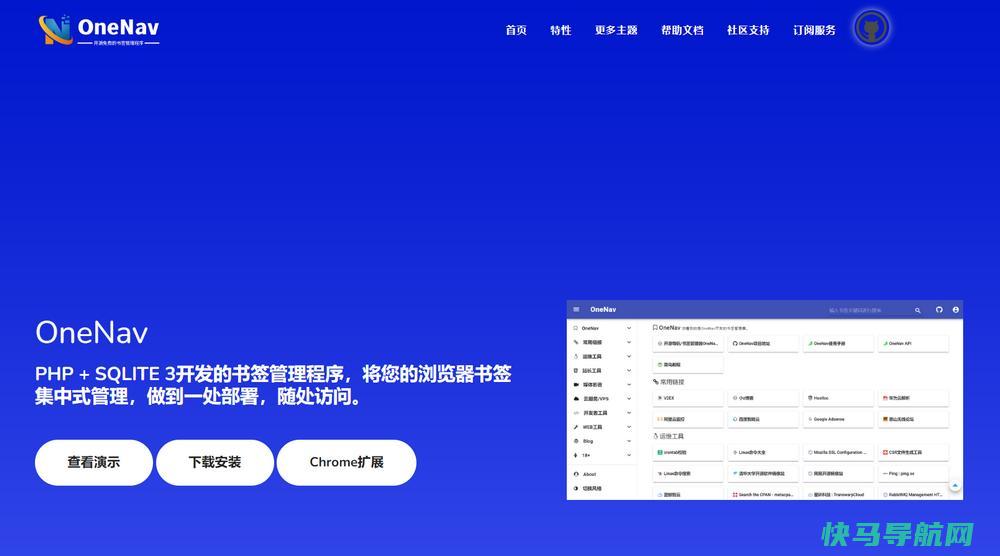
一篇文章带你快速了解开源免费的书签(导航)管理程序OneNav86条评论OneNav是一款开源免费的书签(导航)管理程序,由xiaoz使用使用PHP+SQLite3开发,界面简洁,安装简单,使用方便。OneNav可帮助你你将浏览器书签集中式管理,解决跨设备、跨平台、跨浏览器之间同步和访问困难问题,做到一处部署,随处访问。功能特点安装环...

天钡推出新款四盘位NAS主机WTRPro:英特尔N100,准系统1399元xiaoz之前购买了2台天钡迷你主机,所以一直有关注他们家的产品,最近发现天钡上架了NAS型迷你电脑主机WTRPro,其提供了4个便插式硬盘位,整机采用金属机身,配备双2.5G网口,无内存硬盘的准系统机型售价1399元。购买地址配置外观展示以下是外观展示图片,具...

精选:NAS用户必装的十款软件,让你的NAS发挥极致(上篇)6条评论大家好,我是xiaoz!在这个大数据时代,谁不想让自己的NAS系统更加强大呢?我精选了十款必备NAS软件,旨在帮你充分发挥NAS的价值。无论你是刚开始接触NAS的新手,还是已经是技术达人,这些软件都非常值得尝试。而且好消息是,这些软件支持各种系统,无论是群晖、威联通还...

你有没有通过iPhone或iPad订阅过应用程序?也许这是一个免费试用订阅,需要按月付费才能继续。或者它可能是苹果自己的服务之一,比如AppleMusic或AppleArade,或者是第三方应用程序,比如密码管理器或音乐流媒体服务。无论你如何启动订阅,你都可以很容易地停止它。这个过程相当快,但你需要知道在哪里点击或点击,然后才能拔掉插...
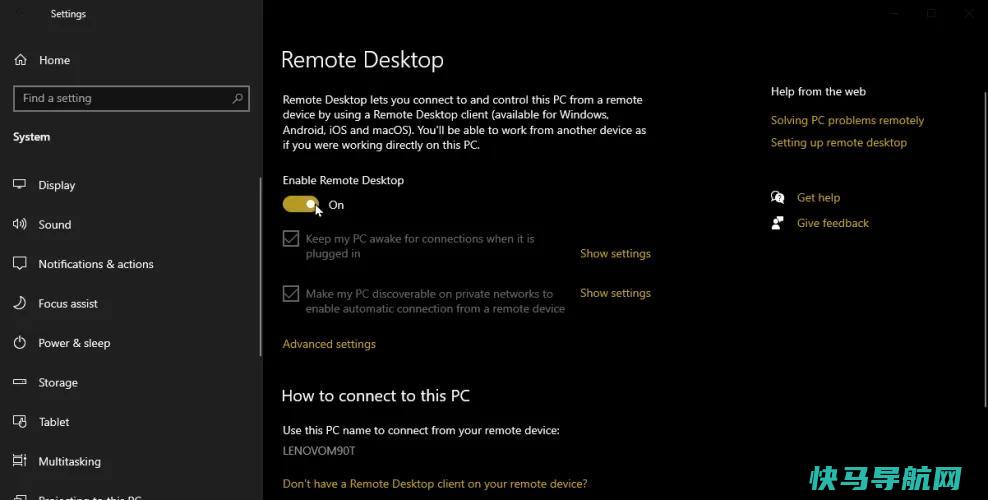
自2020年以来,越来越多的人在家工作。因此,人们对远程访问计算机的需求越来越大。这项工作的一个工具是微软的远程桌面程序,它可以帮助你将家里的电脑连接到办公室的一台电脑上。但如果你没有笔记本电脑,你也可以从苹果或安卓设备上访问远程PC。建立连接后,您可以在移动设备上查看屏幕、打开文件和使用应用程序,就像坐在电脑前一样轻松(尽管可能不会...

在目前的社交媒体环境中,很容易过度分享。通过分析你选择在网上传播的信息,比以往任何时候都更多的人可以找到关于你生活的私密细节。更令人担忧的是,在网上发布你的生活细节会带来安全方面的担忧。你的公共帖子会让你很容易成为广告商、诈骗者、废品邮件制造者、跟踪者和其他所有不受欢迎的人在网上的目标。继续阅读,了解为什么你应该将你的公共社交档案设置...
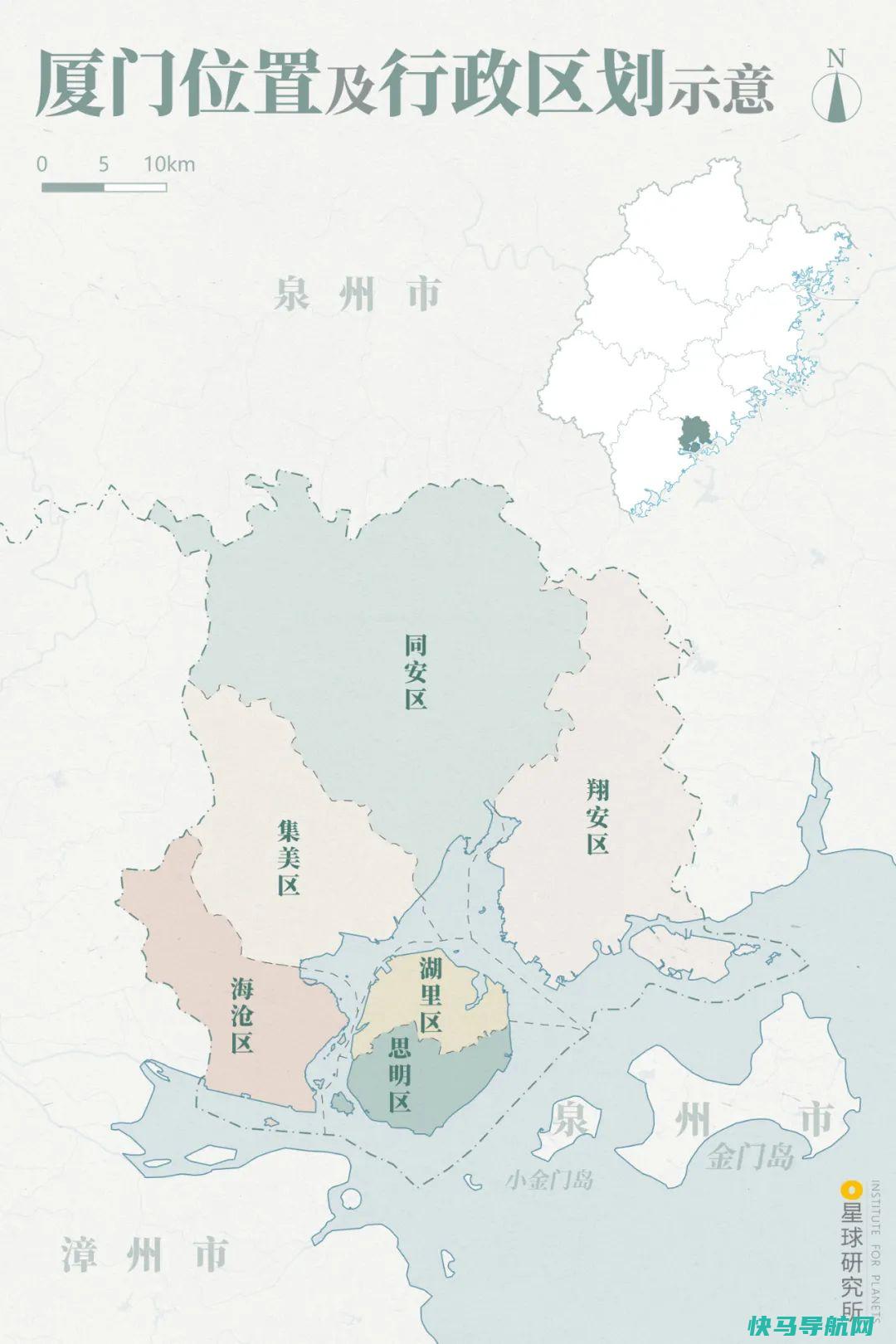
本文目录导航:厦门海沧人才招聘网52岁可以做什么?厦门市海沧区城市管理行政执法局招聘城管协管员招聘5人,我想问下,这个对身高有没有啥要求?2014年福建事业单位招聘信息:厦门市海沧区东孚镇招聘公告厦门海沧人才招聘网52岁可以做什么?这个年龄保洁或者批发市场搞点蔬菜水果出摊卖。厦门市海沧区城市管理行政执法局招聘城管协管员招聘5人,我想问...

大家好,今天小编来为大家解答竹叶是树叶还是草这个问题,关于竹叶的介绍很多人还不知道,现在让我们一起来看看吧!本文目录一、竹子是树还是花1、竹子既不是树也不是花,它属于竹科植物。在植物分类学中,竹子被归类为禾本科(Poaceae)中的竹亚科(Bambusoideae),属于禾本科植物的一种。2、竹子因其坚韧的茎和快速生长的特点而被广泛栽...