 用户中心
用户中心人工智能已经把文字提示变成了令人惊叹的艺术。下一步:视频

Runway已经放弃了中途和稳定的扩散,推出了第一个从文本到视频的人工智能艺术片段,该公司表示,这些片段完全由文本提示生成。
该公司表示,它正在为其首个使用真实世界场景作为模型的更简单的文本到视频工具提供类似的等待名单,以加入它所称的文本到视频人工智能的“第二代”。
当人工智能艺术去年出现时,它使用了文本到图像的模式。用户将输入描述场景的文本提示,该工具将尝试使用它所知道的真实世界的“种子”、艺术风格等来创建图像。中途旅行等服务在云服务器上执行这些任务,而稳定扩散和稳定部落则利用了在家用PC上运行的类似人工智能模型。
然而,文本到视频是下一步。有很多方法可以做到这一点:Pollinations.ai积累了几个你可以尝试的模型,其中一个只是取几个相关的场景,并将它们串在一起构成一个动画。另一款只需创建一个图像的3D模型,并允许您进行缩放。
Runway采取了一种不同的方式。该公司已经提供了人工智能支持的视频工具:从视频中移除对象的修复(而不是图像)、人工智能支持的bokeh、脚本和字幕等。它的第一代文本到视频工具允许你构建一个真实世界的场景,然后将它作为一个模型,在它上面叠加一个文本生成的视频。这通常是以图像的形式进行的,例如,你可以拍摄一张金毛猎犬的照片,然后使用人工智能将照片转换为杜宾犬的照片。
这是第一代。正如该公司在推特上所说,Runway的第二代可以使用现有的图片或视频作为基础。但这项技术也可以完全从文本提示符中自动生成短视频剪辑。
只需文字即可生成视频。如果你能说出来,现在你就能看到它。
简介,文本到视频。与第二代人一起。
正如Runway的推文所指出的那样,这些片段都很短(最多只有几秒钟),非常粗糙,而且帧速率很低。目前也不清楚Runway将于何时发布该模型,以供早期访问或一般访问。但Runway Gen 2页面上的示例确实显示了各种各样的视频提示:纯文本到视频的AI、文本+图像到视频等等。似乎你给模型的投入越多,你的运气就越好。在现有的物体或场景上叠加视频似乎可以提供最流畅的视频和最高的分辨率。
Runway已经提供了12美元/月的“标准”计划,允许无限制的视频项目。但某些工具,比如实际训练你自己的肖像或动物生成器,需要额外支付10美元的费用。目前还不清楚Runway将对其新车型收取多少费用。
然而,Runway展示的是,在短短几个月内,我们已经从文本到图像的人工智能艺术转变为文本到视频的人工智能艺术…我们所能做的就是惊讶地摇头。
外链关键词: 边宁学历东风 青海老师学历名单 餐饮企业成本核算方法 夜场美女 三省六部品牌 民国南京地图 计算机水平考试成绩 逍飞学历本文地址: https://www.q16k.com/article/aa64e948de2c2c973a04.html

MxT -

该站点未添加描述description...
电话号码查询网提供最全的电话号码归属地查询,支持固定电话号码查询、手机号码、企业座机电话归属地查询,其中固定电话详细地址最高可精确到乡镇,还可以查询电话区号、特服电话、短信号码等等。
该站点未添加描述description...

化工设备网(ccen.net)--化工设备、化工机械电子商务网站。涵盖化工设备、化工机械及工程;制药设备、制药机械及工程;环保设备、环保机械及工程。为广大行业机械设备类企业服务。

全人工编辑的开放式网站分类目录,免费收录国内外、各行业优秀网站,旨在为用户提供网站分类目录检索、优秀网站参考、网站推广服务。

360手机助手,8亿用户使用的安卓应用分发平台,年轻人都爱玩的手机助手。
星辰影院免费为您提供最新热播高清电影、电视剧,热门韩剧,欧美大片在线观看,每天更新好看的电视剧,最新综艺秀,明星信息与相关电影电视剧,星辰影院电影网同时提供电影电视剧演员表,角色等相关内容,星辰影院高清影院是影视爱好者们的电影家园!

头像图片为您提供2021最火爆头像图片,个性的男女生微信头像图片,QQ头像图片和像情侣头像图片,数十万个图片头像资源,总会有你想要的头像图片!
360健康网,是实用的健康养生科普知识及日常生活保健小常识大全网站,分享春夏秋冬四季健康饮食养生保健小知识、运动对健康的好处、中医养生食疗做法等健康的生活方式及养生之道,学习健康养生百科知识尽在360健康养生网。

郑码编码查询提供郑码、郑码输入法、郑码在线查询、2024郑码字典、郑码查字法、2024郑码检字法、郑码查询、2024郑码字根表、郑码编码查询、郑码词组、郑码字根查询。

该站点未添加描述description...
该站点未添加描述description...

麦芽地将好玩的手机游戏推荐给大家,整理了大量的热门手游让大家免费下载,还将最新的手游整理成合集大全,快速方便的找到自己喜欢玩的游戏,更有精品的手机必备app,包含了安卓iOS、iPhone苹果的各种免费资源,可享受高速的免费下载服务。

滨州公交查询,滨州公交线路查询,滨州公交地图,滨州市公交,滨州公交车查询路线,公交车线路查询,滨州公交网,滨州公交数据实时更新。
该站点未添加描述description...

洪泰基金
该站点未添加描述description...


在网络枪手的世界里,当你连续五次被服务器另一边的同一[审查]杀死时,将你的死亡归咎于延迟只是略低于指责黑客。但在Valve备受期待的反恐2中,当你向队友道歉的时候,你将有一个更少的选择-假设你无论如何都在使用NVIDIA显卡。即将到来的游戏将使用NVIDIAReflex来应用显卡能力,以减少延迟并提高响应速度。Relex是一个令人着迷...

在过去的几个月里,随着OpenAI革命性的ChatGPT的迅速成功,AI聊天机器人的受欢迎程度急剧上升–令人惊讶的是,直到去年12月左右,ChatGPT才突然出现。但当微软抓住机会,以100亿美元的高价与OpenAI这颗冉冉升起的新星搭上马车时,它选择了这样做,打着谷歌搜索引擎必应(Bing)的幌子,推出了一款基于GPT-4的聊天机器...

还记得几年前,当他们非常努力地尝试让3D电视成为一种东西的时候吗?还记得当你不得不戴笨重的眼镜时,每个人都讨厌它吗?还记得他们试图在没有眼镜的情况下制作3D屏幕,但比史蒂芬·西格尔主演的翻拍电影《音乐之声》更失败了吗?忘了这一切吧,如果你还记得我在说什么的话:宏碁最新推出的Predator笔记本电脑不带眼镜的3D屏幕可能正好能满足你的...
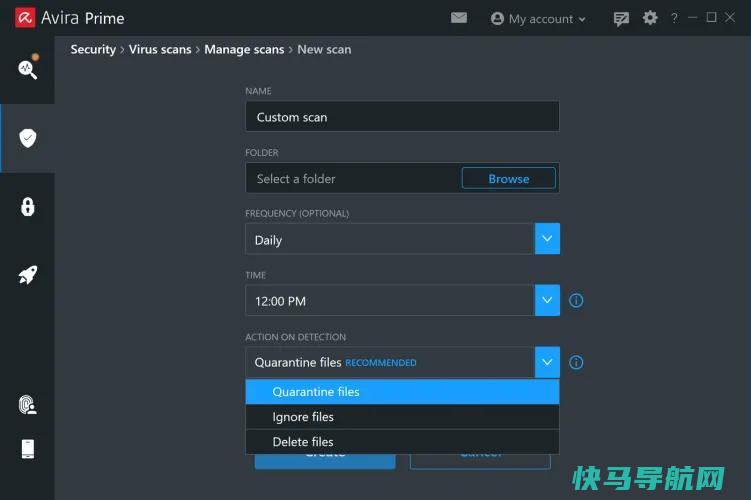
为了提供彻底的保护,今天的安全产品必须做的不仅仅是扫描病毒和恶意软件。他们需要检查有害的互联网流量、侵入性浏览器跟踪、隐私问题、过时的软件和弱密码等项目。一款提供这一切甚至更多功能的产品是AviraPrimeforWindows。AviraPrime专为所有受支持的Windows版本而设计,在一个程序中包含了很多功能。在安全的旗帜下,...

现代时代呼唤现代应用程序。对于Outlook,微软去年开始采取缓慢的步伐,通过发布新的Outlook软件预览版进行全面改革。早期版本对Microsoft365Insider预览版成员开放,限制用户只能使用一个账户–而且必须是属于微软保护伞下的一个账户。但正如Insider的一篇博客文章所宣布的那样,该公司现在已经开始推出第三方电子邮件...

你有没有买过电脑,不是因为它的硬件,而是因为它的软件?不,不是Windows–是应用程序。三星绝对决心你会这样做–并投资于其他三星Galaxy设备,因为它们之间的互动非常好。你可以买一台惠普笔记本电脑、一部谷歌Pixel手机和一台亚马逊Fire平板电脑。或者,你可以买一台三星GalaxyBook3、一台GalaxyTab平板电脑和一部...

呼唤所有的音乐艺术家!无论你是计划制造最糟糕的低音音效,还是仅仅是一些冰冷的低保真音响,你都需要一台坚固的笔记本电脑来完成这项工作。在选择用于音乐制作的笔记本电脑时,有几个关键问题需要注意。高质量的处理器对于流畅的录制性能是绝对至关重要的,而相当大的RAM将允许您同时处理多个插件和曲目。便携性也是一个重要因素–如果你要把你的节目带到当...
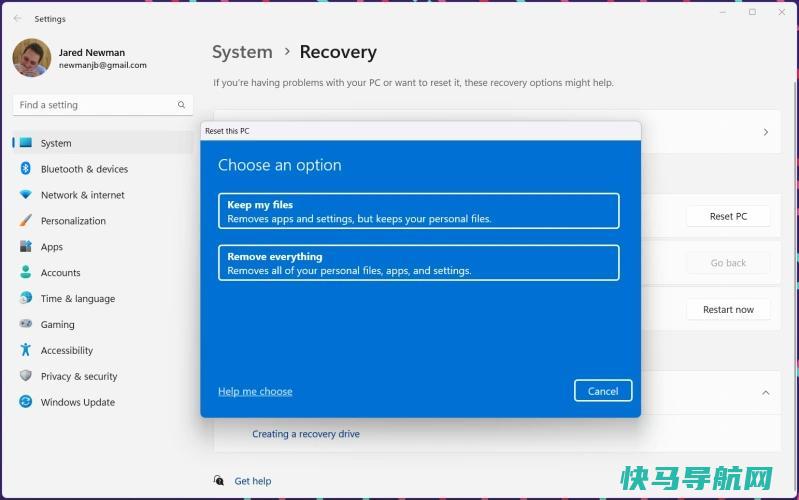
在许多电脑游戏玩家的生活中,有一段时间他们必须做以前无法想象的事情,并在客厅里安装一个游戏设备。也许是因为你在家工作,不能忍受下班后弓着身子坐在同一张桌子前玩游戏,或者你终于买了一台具有VRR等严肃游戏功能的电视,想要一台合适的PC来使用它。或者,也许你已经尝到了用蒸汽甲板解放你的电脑游戏库的滋味,并想把这些游戏带到家里更多的屏幕上。...

OLED显示器在2023年风靡一时,但令日常购物者失望的是,它们仍然很贵。即使是便携式OLED显示器,价格通常也在300美元以上。但是,虽然Innocn15K1F的建议零售价为399.99美元,但它在亚马逊上的价格要低得多(撰写本文时为269.99美元),为消费者提供了一种廉价的选择,仅略低于价格更高的竞争对手。Innocn15K1F...

事实证明,谷歌对可以上传到其云存储服务GoogleDrive的文件数量施加了硬性限制–尽管缺乏概述这些限制的明确文件。那个神奇的数字?五百万。更新日期23年4月5日:谷歌正在取消Drive账户的文件数限制。在GoogleDriveTwitter账户上的一条推文中,该公司表示,它已经改变了政策,同时寻求其他方法来提高服务的性能。Goog...

还记得希捷制作特别版存储驱动器时用的是“贝斯卡钢材”吗?波巴·费特和其他曼达洛人都穿这种材料来制作它们。销路非常好不受等离子爆破器的影响?好的,该公司带着星球大战口味的PC硬件回来了,这一次它更闪亮了。新的“LightsaberCollection”FireCudaM.2固态硬盘配有可更换的面板,通过Kyber注入的LED发光二极管点...

2月底,AMDRyzen97950X3D的发布充分说明了一件事:TeamRed的7000系列3DV-Cache处理器中的第一个是游戏怪物。他们额外增加了一层辛辣的L3缓存层,大大提高了他们的性能。但所有人都在等待的芯片–Ryzen77800X3D–仍然是一个问号。与售价699美元的7950X3D和599美元的Ryzen97900X3D...

联想的消费笔记本旗舰产品Yoga9i在2023年基本没有变化,但有一些值得注意的升级,包括英特尔酷睿第13代处理器和标准OLED显示屏(这在以前是一个选项)。这些改进与竞争并驾齐驱,尽管它们也会导致更高的价格。正在寻找更多2合1选项?查看我们今天提供的最好的2合1笔记本电脑综述。联想Yoga9i采用英特尔全新酷睿i7-1360P处理器...

罗技G502在2014年就让游戏玩家惊叹不已,但后来又发生了变化,最终推出了新的改进版G502X。是的,它有一个升级的25K英雄传感器,可以很好地提高速度和精度,但G502X最令人印象深刻的是按钮被磨练到近乎完美的方式。很少有游戏鼠标有如此易用的按钮布局,这总是使这款新型号成为2023年你可以购买的最好的全能有线游戏鼠标之一。注:查看...
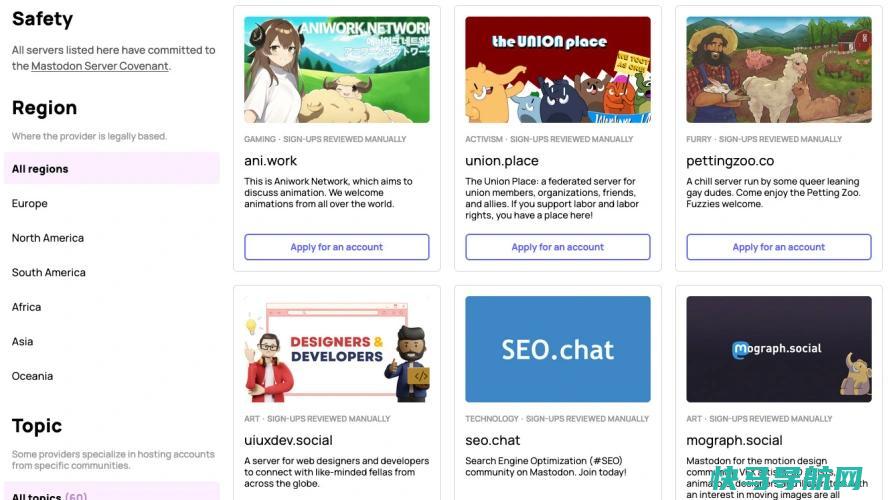
埃隆·马斯克最近宣布,在一系列有利于付费客户的变化中,旧的复选标记正在消失,这似乎正在推动另一批人离开Twitter去中心化的微博服务Mastodon。但想要成为Mastodon用户的人往往在第一步就放弃了:选择一台服务器来创建账户。虽然Mastodon与其他社交媒体服务不同,但它也远没有乍看起来那么令人生畏。我们分析了Mastodo...
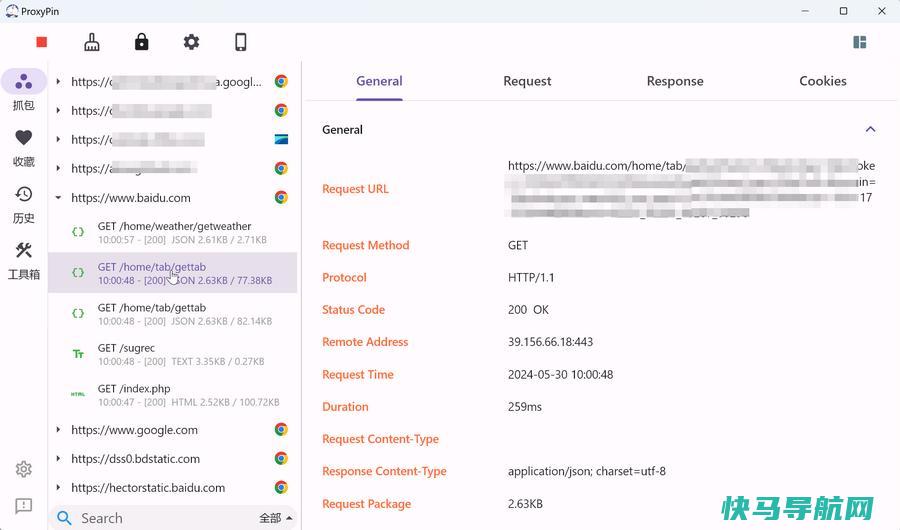
探索ProxyPin:开源免费的全平台HTTP抓包工具ProxyPin是一款开源抓包工具,它支持多种操作系统包括Windows、Mac、Android、IOS和Linux。该工具使用Flutter开发,界面美观易用。它使用户能够拦截、检查和重写HTTP(S)流量,非常适合开发人员或运维人员使用。ProxyPin特性安装ProxyPin...

在Windows11中,微软团队长期以来一直是强加给用户的应用程序,而不是向他们提供帮助的应用程序。有没有过和朋友聊天,却有一个完全陌生的人走上前来加入进来,就像他们一直被邀请聊天一样?Windows11的S任务栏内置了团队聊天功能,一直带有这种感觉–你必须特别排除它,否则它会继续尴尬地出现在你的其他快捷方式图标中。但在最新的Wind...

如果你是一名无法抑制的科技新闻爱好者,你可能听说过英特尔处理器的价格正在上涨,特别是构成该公司大部分业务的酷睿CPU。根据英特尔自己的说法,这些价格上涨并没有发生。该公司罕见地直接驳斥了这一报道,给炙手可热的谣言工厂泼了一盆冷水。这个故事始于一个德国用户论坛,引用了英特尔给零售合作伙伴的一封未经证实的信,随后欧洲新闻出版物上涌现出令人...

今天,lanpanpan.com推出了SmartAnswers,这是一个聊天机器人工具,可以帮助您从我们的内容中获得更多信息。它是使用生成性人工智能和我们的人类编辑编写的现有内容构建的。我们与内容互动的方式正在发生变化。就在不久前,你还会在纸质杂志上筛选关于最新消费技术的建议,但当那些旧杂志转向数字和在线版本时,感觉就像是一场革命。如...

如果你想在周末玩一些很棒的游戏,又不想花一分钱,那么从EpicGames商店下载的最新免费游戏就是你最合适的选择。战略游戏HomeWorld:沙漠ofKharak将免费提供至8月31日。这款游戏于2016年发布,获得了我们强烈的4星评价,我们的测试人员称其为“经典复活”。沙漠中的战斗就像标志性的HomeWorld系列中的原始游戏一样,...