 用户中心
用户中心谷歌 TPU 超级算力大模型已超英伟达
尽管目前尚无与 chatgpt 匹敌的AI大型模型,但在计算能力方面,领导者可能并非微软和 OpenAI。目前,谷歌发布了其基于 TPU 的超级计算机在训练大型语言模型方面的详细信息,该超级计算机在速度和能效方面已经超过了英伟达的同类产品。
 谷歌张量处理器(Tensor processing Unit,TPU)是该公司为机器学习定制的专用集成电路(Application-Specific Integrated Circuit,ASIC)。自2016年发布第一代以来,TPU 便成为了 AlphaGo 背后的算力。与 GPU 相比,TPU 采用低精度计算,在几乎不影响深度学习处理效果的前提下显著降低了功耗并加快了运算速度。此外,TPU采用了脉动阵列等设计来优化矩阵乘法和卷积运算。目前,谷歌90%以上的人工智能训练任务都在使用这些芯片,而TPU支持了包括搜索在内的谷歌的主要业务。图灵奖获得者、计算机架构领域的杰出人物大卫・帕特森(David Patterson)在2016年从 UC Berkeley 退休后,以杰出工程师的身份加入了谷歌大脑团队,为几代 TPU 的研发做出了突出贡献。
谷歌张量处理器(Tensor processing Unit,TPU)是该公司为机器学习定制的专用集成电路(Application-Specific Integrated Circuit,ASIC)。自2016年发布第一代以来,TPU 便成为了 AlphaGo 背后的算力。与 GPU 相比,TPU 采用低精度计算,在几乎不影响深度学习处理效果的前提下显著降低了功耗并加快了运算速度。此外,TPU采用了脉动阵列等设计来优化矩阵乘法和卷积运算。目前,谷歌90%以上的人工智能训练任务都在使用这些芯片,而TPU支持了包括搜索在内的谷歌的主要业务。图灵奖获得者、计算机架构领域的杰出人物大卫・帕特森(David Patterson)在2016年从 UC Berkeley 退休后,以杰出工程师的身份加入了谷歌大脑团队,为几代 TPU 的研发做出了突出贡献。
 如今,TPU 已发展至第四代。4月11日,由 Norman Jouppi、大卫・帕特森等人发表的论文《TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings》详细阐述了谷歌如何利用自研光通信器件将 4000 多个芯片并联组成超级计算机,从而提升整体效能。相较于 TPU v3,TPU v4 性能提升了2.1倍,功耗性能比增加了2.7倍。基于 TPU v4 的超级计算机拥有 4096 个芯片,整体速度提升约10倍。与类似规模的系统相比,谷歌的 TPU v4 比 Graphcore IPU Bow 快4.3-4.5倍,比 Nvidia A100 快1.2-1.7倍,功耗降低1.3-1.9倍。除了芯片本身的计算能力外,芯片间互连已成为构建AI超级计算机的企业间竞争的关键因素。近期,大型语言模型(LLM)如谷歌的 Bard 和 OpenAI 的的规模正呈爆炸式增长,计算能力已经成为显著的瓶颈。由于大型模型通常具有千亿级的参数量,数千个芯片必须共同分担训练任务,且训练过程可能持续数周甚至更长时间。谷歌的PaLM模型——迄今为止该公司披露的最大规模语言模型——在训练过程中被分配到两台拥有4000个TPU芯片的超级计算机上,耗时50天。谷歌表示,通过光电路交换机(Optical Circuit Switch, OCS),其超级计算机可以轻松地动态重新配置芯片间的连接,有助于避免问题并实时调整以提高性能。下图展示了 TPU v4 4×3 配置中的6个“面”的连接方式。每个面包含16条链路,每个模块总共有96条光链路连接到 OCS。为了提供3D环面的环绕连接,相对侧的连接必须接入相同的 OCS。因此,每个4×3模块的TPU连接到6×16÷2=48个 OCS。Palomar OCS 具有136×136规格(128个端口加上8个用于链路测试和修复的备用端口),因此来自64个4×3模块(每个包含64个芯片)的48对电缆共连接了48个 OCS,总计并联4096个 TPU v4 芯片。
如今,TPU 已发展至第四代。4月11日,由 Norman Jouppi、大卫・帕特森等人发表的论文《TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings》详细阐述了谷歌如何利用自研光通信器件将 4000 多个芯片并联组成超级计算机,从而提升整体效能。相较于 TPU v3,TPU v4 性能提升了2.1倍,功耗性能比增加了2.7倍。基于 TPU v4 的超级计算机拥有 4096 个芯片,整体速度提升约10倍。与类似规模的系统相比,谷歌的 TPU v4 比 Graphcore IPU Bow 快4.3-4.5倍,比 Nvidia A100 快1.2-1.7倍,功耗降低1.3-1.9倍。除了芯片本身的计算能力外,芯片间互连已成为构建AI超级计算机的企业间竞争的关键因素。近期,大型语言模型(LLM)如谷歌的 Bard 和 OpenAI 的的规模正呈爆炸式增长,计算能力已经成为显著的瓶颈。由于大型模型通常具有千亿级的参数量,数千个芯片必须共同分担训练任务,且训练过程可能持续数周甚至更长时间。谷歌的PaLM模型——迄今为止该公司披露的最大规模语言模型——在训练过程中被分配到两台拥有4000个TPU芯片的超级计算机上,耗时50天。谷歌表示,通过光电路交换机(Optical Circuit Switch, OCS),其超级计算机可以轻松地动态重新配置芯片间的连接,有助于避免问题并实时调整以提高性能。下图展示了 TPU v4 4×3 配置中的6个“面”的连接方式。每个面包含16条链路,每个模块总共有96条光链路连接到 OCS。为了提供3D环面的环绕连接,相对侧的连接必须接入相同的 OCS。因此,每个4×3模块的TPU连接到6×16÷2=48个 OCS。Palomar OCS 具有136×136规格(128个端口加上8个用于链路测试和修复的备用端口),因此来自64个4×3模块(每个包含64个芯片)的48对电缆共连接了48个 OCS,总计并联4096个 TPU v4 芯片。
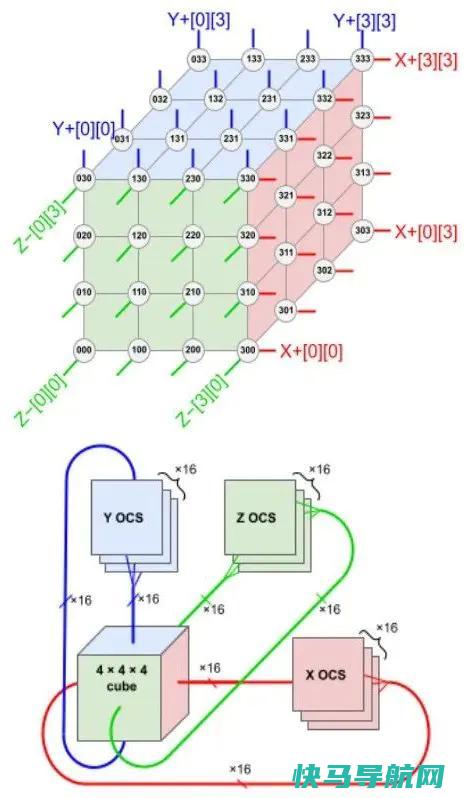 根据这样的排布,TPU v4(中间的 ASIC 加上 4 个 HBM 堆栈)和带有 4 个液冷封装的印刷电路板 (PCB)。该板的前面板有 4 个顶部 PCIe 连接器和 16 个底部 OSFP 连接器,用于托盘间 ICI 链接。随后,八个 64 芯片机架构成一台 4096 芯片超算。
根据这样的排布,TPU v4(中间的 ASIC 加上 4 个 HBM 堆栈)和带有 4 个液冷封装的印刷电路板 (PCB)。该板的前面板有 4 个顶部 PCIe 连接器和 16 个底部 OSFP 连接器,用于托盘间 ICI 链接。随后,八个 64 芯片机架构成一台 4096 芯片超算。
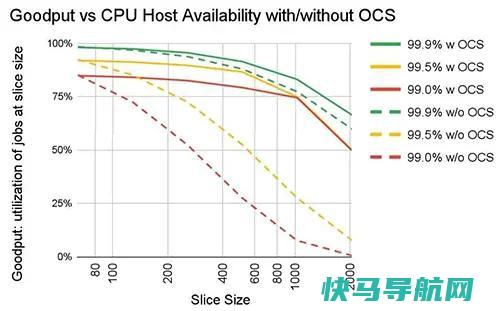
 在超级计算机中,工作负载由不同规模的算力承担,称为切片,如64芯片、128芯片、256芯片等。下图展示了在主机可用性从99.0%到99.9%不等,以及在没有 OCS 时,不同切片大小的“有效输出”。若无 OCS,主机可用性必须达到99.9%才能提供合理的切片吞吐量。对于大多数切片大小,OCS 在99.0%和99.5%的可用性下也表现出良好的输出。
在超级计算机中,工作负载由不同规模的算力承担,称为切片,如64芯片、128芯片、256芯片等。下图展示了在主机可用性从99.0%到99.9%不等,以及在没有 OCS 时,不同切片大小的“有效输出”。若无 OCS,主机可用性必须达到99.9%才能提供合理的切片吞吐量。对于大多数切片大小,OCS 在99.0%和99.5%的可用性下也表现出良好的输出。
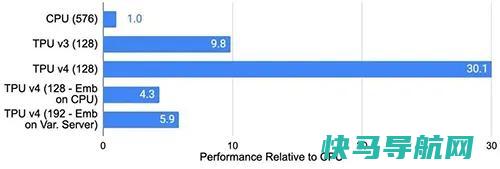
 与Infiniband相比,OCS 具有更低的成本、更低的功耗和更快的速度,占据系统成本不到5%,系统功率不到3%。每个 TPU v4 都包含 SparseCores 数据流处理器,能将依赖嵌入的模型加速5至7倍,但仅占用5%的裸片面积和功耗。谷歌研究员 Norm Jouppi 和谷歌杰出工程师大卫・帕特森在一篇关于该系统的博客文章中写道:这种切换机制使得绕过故障组件变得容易,其灵活性甚至允许我们改变超级计算机互连的拓扑结构,以加速机器学习模型的性能。TPU v4 比当代 DSA 芯片速度更快、功耗更低,如果考虑到互连技术,功率边缘可能会更大。通过使用具有 3D 环面拓扑的 3K TPU v4 切片,与 TPU v3 相比,谷歌的超算也能让 LLM 的训练时间大大减少。下图展示了谷歌自用的推荐模型(DLRM0)在不同芯片上的效率。TPU v3 比 CPU 快 9.8 倍。TPU v4 比 TPU v3 高 3.1 倍,比 CPU 高 30.1 倍。
与Infiniband相比,OCS 具有更低的成本、更低的功耗和更快的速度,占据系统成本不到5%,系统功率不到3%。每个 TPU v4 都包含 SparseCores 数据流处理器,能将依赖嵌入的模型加速5至7倍,但仅占用5%的裸片面积和功耗。谷歌研究员 Norm Jouppi 和谷歌杰出工程师大卫・帕特森在一篇关于该系统的博客文章中写道:这种切换机制使得绕过故障组件变得容易,其灵活性甚至允许我们改变超级计算机互连的拓扑结构,以加速机器学习模型的性能。TPU v4 比当代 DSA 芯片速度更快、功耗更低,如果考虑到互连技术,功率边缘可能会更大。通过使用具有 3D 环面拓扑的 3K TPU v4 切片,与 TPU v3 相比,谷歌的超算也能让 LLM 的训练时间大大减少。下图展示了谷歌自用的推荐模型(DLRM0)在不同芯片上的效率。TPU v3 比 CPU 快 9.8 倍。TPU v4 比 TPU v3 高 3.1 倍,比 CPU 高 30.1 倍。
 性能、可扩展性和可用性使 TPU v4 超级计算机成为 LaMDA、MUM 和 PaLM 等大型语言模型 (LLM) 的主要算力。这些功能使 5400 亿参数的 PaLM 模型在 TPU v4 超算上进行训练时,能够在 50 天内维持 57.8% 的峰值硬件浮点性能。谷歌表示,其已经部署了数十台 TPU v4 超级计算机,供内部使用和外部通过谷歌云使用。
性能、可扩展性和可用性使 TPU v4 超级计算机成为 LaMDA、MUM 和 PaLM 等大型语言模型 (LLM) 的主要算力。这些功能使 5400 亿参数的 PaLM 模型在 TPU v4 超算上进行训练时,能够在 50 天内维持 57.8% 的峰值硬件浮点性能。谷歌表示,其已经部署了数十台 TPU v4 超级计算机,供内部使用和外部通过谷歌云使用。
本文地址: https://www.q16k.com/article/b0727caac436330a243b.html

Win7之家是Win7系统下载站,提供Win7纯净版,Win7旗舰版,windows7旗舰版,ghost win7等Win7 32位系统下载及Win7 64位系统下载.更多Windows7旗舰版,Ghost Win7 sp1,Win7装机版敬请关注Win7之家官网。

情感屋-情感故事,情感美文,情感日志,情感日记,情感图片
百度安全响应中心联合广大的白帽子,以建设安全的互联网为己任!

怎么加入污水宝会员?为您提供快速入驻通道,欢迎环保产业链相关企业入驻污水宝平台合作。
玛诗特小说网是广大书友最值得收藏的网络小说阅读网,玛诗特小说网收录了当前最火热的网络小说,玛诗特小说网免费提供高质量的小说最新章节,玛诗特小说网是广大网络小说爱好者必备的小说阅读网。
该站点未添加描述description...

三千云建站,一站式网站建设系统和建站平台,14天免费体验,7天无理由退款,可视化编辑!满足企业网站建设、网站设计制作、建网站、免费建站、网站搭建、企业网站制作、定制网站等需求,好用的模板建站,建站系统,企业用户建站之选。

妈祖灵签提供:天后灵签,妈祖天后灵签在线抽签,妈祖灵签抽签,妈祖灵签解签,妈祖灵签详解,妈祖灵签1-60签解签,莆田妈祖天后灵签总共有六十支,妈祖是保护海上安全的神灵。
该站点未添加描述description...
该站点未添加描述description...
Zhejiang Yili Machinery & Electric is a manufacturer who focuses on all kinds of cleaning equipment and relative products.

该站点未添加描述description...
该站点未添加描述description...
该站点未添加描述description...

该站点未添加描述description...
该站点未添加描述description...
姚剑浩(个人),姚剑浩(个人),服装女式T恤


Web3这个词对于币圈的人来说,肯定再熟悉不过了。但对于普通用户很多人还对这个概念一只半解,那么,Web1.0、Web2.0和Web3.0之间有什么区别?本文狂人SEO为大家解答一下这三者的区别,以及我们为何要建设Web3。一、什么是Web1.0互联网的第一代,被称为Web1.0,是个人计算机(PC)互联网的时代,自1994年开始发展...

在加密货币领域,稳定币扮演着非常重要的角色。与BTC、ETH和BNB等其他加密货币相比,稳定币是安全的、没有剧烈波动的,更适合用作交易媒介和存储价值的工具。本文跟大家讲下稳定币是什么?稳定币有什么作用?一、稳定币是什么?稳定币,顾名思义,是一种设计来保持其市值稳定的数字货币,通常是与某种固定资产挂钩。目前为止,大多数稳定币都与美元挂钩...

如今我们的工作与生活都离不开电脑和网络,虽然手机也可以处理很多事情,但有些问题仍然需要通过电脑来解决,在联网的时候有些网友可能会碰上宽带连接错误769无法连接指定目标的情况,今天跟大家讲下出现宽带连接错误769这个提示的解决方法是什么?先讲下可能出现此提示的原因:1、电脑网线断开了;2、网卡已被禁用;3、网卡的驱动程序已经损坏;4、W...
平常我们在工作中会创建和编辑各种文档,特别是使用MicrosoftWord处理文字和信息的时候,可能会碰上需要在文档中添加打勾的小方框,这样用来标记任务、勾选清单或其他目的。其实并不难,只需按照以下几个步骤,你就可以松搞定。1、我以office2016版本为例,打开Word,上方导航栏选择“插入”选项卡,然后往右找到“符号”,如图:2...

Twitter是一个广受欢迎的社交网络平台,允许用户将自己的最新动态和想法以推文形式发布,和国内的微博是一样的效果,不过它面对的是全世界的用户。今天狂人SEO分享给大家2023年推特帐号注册的图文详细教程。一、推特注册前期准备1、苹果手机通过APPStore自行下载,需要苹果海外账号,国内无法下载。安卓手机可以通过访问推特移动网站(有...

当前加密货币的发展与过去几年相比,除了概念更广为人之,另一个是应用变得更加丰富多元,玩法也越来越吸引人。以太坊历经几年的发展,NFT与DeFi成为平台上最热门的2款APP类别,许多人参与其中,希望能摸索出下一步。本文狂人SEO跟大家普及下什么是NFT与什么是DeFi,以及两者的区别。一、什么是NFTNFT(Non-FungibleTo...

核能事故,如近期的福岛事件,都提醒我们核辐射的危害。事故发生后,大量的放射性物质被释放到环境中,导致土壤、水和食物链中的食品被污染。那么,食用这些受到核污染的食品会带来怎样的后果?我们需要多么担忧这些风险?这篇文章将为你详细解答。一、核污染的影响因素核污染对人体的影响程度取决于多个因素,包括以下几个方面:1、放射性物质的种类:不同种类...
Telegram我们也称为电报、纸飞机,是一款全球化的即时聊天工具。与WhatsApp不同,电报APP无法将用户的聊天记录备份到云服务,而TelegramAPP也无法直接备份这些资料,必需通过PC端,本文狂人SEO跟大家分享Telegram导出用户、群组、聊天记录、图片等资料的方法。1、梯子连接好,访问网址desktop.telegr...

Telegram(通常被称为TG、电报/纸飞机)是目前全球最流行的即时通讯应用之一。其基本功能与大多数同类聊天软件相似:允许用户向其他用户发送信息,建立群组对话,呼叫联系人,进行视频聊天,以及发送文件和表情。今天狂人SEO跟大家分享Telegram账户注册的详细教程。1、通过科学上网工具访问telegram.org(没有工具或收不到验...
我们在申请一些美国服务或注册账户时,有时会需要提供一个美国地址。尽管可以通过美国地址生成器获取一个地址,但这个地址可能不是真实的,无法通过网站的地址验证。实际上,获取一个真实的美国地址非常简单,只需打开Google地图,就能找到无数符合要求的真实美国地址。此外,还可以通过谷歌街景地图查看该地址是住宅还是商店,以及其外观如何,从而判断地...
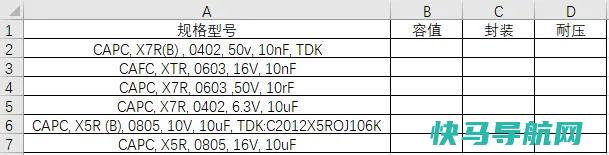
我们在日常办公使用Excel软件制表时,有时会需要对单元格内的部分数据进行提取,比如电话号码的区号,当数据量大时,逐个复制粘贴显然效率不高,也容易出错。其实有专门的数据提取公式可以轻松处理,本文狂人SEO跟大家分享。我们通过以下这份表来示范快速提取单元格部分数值的方法:我们看到A列每个单元格有多项数据,现在需要从中提取出容值、封装和耐...
尽管目前尚无与ChatGPT匹敌的AI大型模型,但在计算能力方面,领导者可能并非微软和OpenAI。目前,谷歌发布了其基于TPU的超级计算机在训练大型语言模型方面的详细信息,该超级计算机在速度和能效方面已经超过了英伟达的同类产品。谷歌张量处理器(TensorProcessingUnit,TPU)是该公司为机器学习定制的专用集成电路(A...

随着互联网的普及和电子商务的迅速发展,我们已习惯于在线购物,以享受更多的选择和便利。俄罗斯,作为世界上面积最大的国家,其电子商务市场也在不断壮大。本文狂人SEO为大家介绍俄罗斯主流的电商平台,以便你了解当地的在线购物市场。一、速卖通(aliexpress.ru)AliExpress是阿里巴巴旗下的电子商务零售平台,服务全球买家,被广大...

由于一些应用无法上架中国大陆的AppStore,而国外苹果账号可以访问完整的iTunesStore,或者订阅AppleArcade精品游戏等,所以我们会需要使用外区AppleID从国外AppStore下载安装。本文狂人SEO跟大家免费分享苹果手机如何注册美区AppleID账号?一、注册AppleID准备工作一个能接收短信的国内手机号;...

对于外贸企业而言,不论是通过海关数据、Google或其他途径,我们的最终目标都是出单。然而,信息获取的渠道和途径繁多,通常需要整合多个来源才能获得完整的信息。在国际贸易中,海关数据具有重要地位,它既是贸易数据的基础,也是外贸人员开发客户的必备工具。本文狂人SEO分享下海关数据是什么?能为外贸企业创造什么价值?一、海关数据是什么?海关数...

在过去的几年里,我们的生活和工作方式发生了很大的变化,最大的不同是从办公室工作转变为在家工作。这意味着你需要在你的家庭办公室使用工作工具,而最基本的是电话线。许多企业已经过渡到IP语音(VoIP)电话服务,这种服务通过互联网而不是传统的电话线连接呼叫。这意味着,只要您的家中有高速互联网连接,远程IT部门为您安装和管理电话线就相对容易。...

一天有多少次导航到Google.com在互联网上查找东西?现代浏览器允许你直接从地址栏进行搜索,所以几乎没有理由加载谷歌搜索的主页,但一些人无法摆脱这个习惯。如果这就是你,至少可以根据你的需要进行定制。下面是如何设置的方法。打开GoogleSearchDark模式Google.com的基本美学让事情变得简单……而又明亮。在黑暗模式下将...

苹果iPhone于2007年上市,运行的是一款未具名的操作系统。一年后,它得到了一个无聊的绰号:iPhoneOS1。到2010年,营销部门齐心协力,推出了“iOS”,正好赶上第四版的首次亮相。我们现在到了iOS17,在过去的15年里,iOS经历了一系列的变化–从接受专用应用程序(版本2)和取消平面图像的偏态(IOS7),到最终接受小部...

购买翻新的技术而不是全新的设备有一个简单的原因–为了省钱。避免将另一个小玩意儿送到废品填埋场也很好。一个额外的好处是:如果你选择翻新的产品,它不会受到发货延迟的影响,而全新的设备可能会。问题是,翻新过的产品以前有过生命。也许这只是一个细心的原始主人的短暂存在,但也可能不是。你所知道的是,产品被退回了,并进行了大修,以使其再次可行,或者...

本文目录导航:溧水建设银行有哪些支行溧水和凤镇有主管房屋建设的部门吗南京溧水区迎来大发展,大批城市新地标偷偷崛起,你了解哪个呢?溧水建设银行有哪些支行南京溧水珍珠桥支行、南京溧水支行、大东门支行。根据查询网络地图显示。1、南京溧水珍珠桥支行:地址位于江苏省南京市溧水区通济街11号。营业时间:周一至周五08:30至11:30,14:00...