 用户中心
用户中心如何免费(和私下)运行自己的类似ChatGPT的LLM

像 ChatGPT 这样的大型语言模型(LLM)的力量是显而易见的,通常通过云计算实现,但你有没有想过在自己的笔记本电脑或台式机上运行AI聊天机器人?根据您的系统的现代化程度,您可能可以在自己的硬件上运行LLMS。但你为什么要这么做呢?
好吧,也许您想要针对您自己的数据微调一个工具。也许你想让你的人工智能对话保持私密和离线。你可能只想看看人工智能模型能做什么,而不是运行云服务器的公司关闭他们认为不可接受的任何对话话题。在您自己的硬件上使用类似ChatGPT的LLM,所有这些场景都是可能的。
硬件并不像你想象的那样是个障碍。最新的LLM经过优化,可以与NVIDIA显卡和使用Apple M系列处理器的Mac电脑一起使用-甚至是低功耗的覆盆子PI系统。随着新的专注于人工智能的硬件上市,比如英特尔“流星湖”处理器的集成NPU或AMD的Ryzen AI,本地运行的聊天机器人将比以往任何时候都更容易获得。
多亏了拥抱脸这样的平台和Reddit的LocalLlaMA这样的社区,ChatGPT等轰动一时的工具背后的软件模型现在已经有了开源的等价物–事实上,在撰写本文时,有超过20万种不同的模型可用。此外,多亏了Oobaboga的文本生成WebUI等工具,你可以在浏览器中使用类似于ChatGPT、Bing Chat和Google Bard的干净、简单的界面来访问它们。
因此,简而言之:本地运行的人工智能工具是免费提供的,任何人都可以使用它们。然而,它们都不是为非技术用户现成的,而且这一类别足够新,您不会找到许多关于如何下载和运行您自己的LLM的易于消化的指南或说明。同样重要的是要记住,本地LLM不会像云服务器平台那样快,因为它的资源仅限于您的系统。
然而,我们在这里帮助好奇的人,一步一步地指导你在自己的电脑上设置自己的ChatGPT替代方案。我们的指南使用的是Windows计算机,但这里列出的工具通常也适用于Mac和Linux系统,尽管在使用不同的操作系统时可能会涉及一些额外的步骤。
有关在本地运行LLMS的一些警告
然而,首先,有几个警告–划掉,很多警告。正如我们所说的,这些模型是免费的,由开源社区提供。他们依赖于许多其他软件,这些软件通常也是免费和开源的。这意味着一切都是由单独的程序员和志愿者团队以及Facebook和微软等几家大公司共同维护的。重点是你会遇到很多移动部件,如果这是你第一次使用开源软件,别指望它会像在手机上下载一个应用程序那么简单。相反,这更像是在你还没有考虑下载你想要的最终应用程序之前就安装了一堆软件–然后可能仍然无法工作。而且,无论我们试图使这本指南多么全面和用户友好,您可能会遇到我们不能在一篇文章中解决的障碍。
此外,寻找答案也可能是一件真正的痛苦。致力于这些主题的在线社区通常有助于解决问题。通常,有人已经解决了你在网上通过搜索就能找到的对话中遇到的问题。但这段对话在哪里呢?它可能在Reddit上、在FAQ中、在GitHub页面上、在HuggingFace的用户论坛上,或者在其他完全不同的地方。
值得一提的是,开源人工智能发展迅速。每天都有新的模型发布,用于与它们互动的工具几乎同样频繁地变化,基本的训练方法和数据以及所有支撑这一点的软件也是如此。作为一个可以写作或潜水的话题,人工智能是流沙。一切都在快速变化,环境也在不断地经历着巨大的变化。因此,在更新和更好的LLM和客户端发布之前,这里讨论的许多软件可能不会持续很长时间。
一句话:风险自负。开源软件没有极客小组可以求助;也不是完全由专业人员维护;你也不会发现可以阅读的方便手册,也没有客户服务部门可以求助–只有一堆组织松散的在线社区。
最后,一旦你运行了所有这些人工智能模型,这些模型都有不同程度的润色,但它们都带有相同的警告:不要相信它们表面上说的话,因为它往往是错误的。永远不要指望人工智能聊天机器人帮助你做出健康或财务决策。同样的道理也适用于写你的学校论文或你的网站文章。此外,如果人工智能说了一些冒犯的话,尽量不要把它当成是针对个人的。它不是一个做出判断或说出有问题的意见的人;它是一个统计单词生成器,用来吐出大多数容易辨认的句子。如果这一切听起来太可怕或乏味,这可能不是一个适合你的项目。
选择您的硬件
在开始之前,您需要了解一些关于您想要在其上运行LLM的机器的信息。它是Windows PC、Mac还是Linux机顶盒?本指南将再次侧重于Windows,但参考的大多数资源都为其他操作系统提供了其他选项和说明。
您还需要知道您的系统是否具有独立的GPU或依赖其CPU的集成显卡。大量开源LLM可以仅在您的CPU和系统内存上运行,但大多数LLM都是为了利用专用图形芯片的处理能力及其额外的视频RAM而设计的。游戏笔记本电脑、台式机和工作站更适合这些应用程序,因为它们拥有这些型号经常依赖的强大图形硬件。

在我们的案例中,我们使用的是联想Legion Pro 7i Gen 8游戏笔记本电脑,它结合了强大的英特尔酷睿i9-13900HX CPU、32 GB系统RAM和强大的NVIDIA Geforce RTX 4080移动图形处理器以及12 GB专用VRAM。
如果您使用的是Mac或Linux系统,依赖于CPU,或者正在使用AMD而不是Intel硬件,请注意,虽然本指南中的一般步骤是正确的,但您可能需要额外的步骤和其他或不同的软件来安装。你看到的表现可能与我们在这里讨论的截然不同。
设置您的环境和所需依赖项
要开始,你必须下载一些必要的软件:Microsoft Visual Studio 2019。任何更新的Visual Studio 2019版本都可以运行(尽管不是较新的年化版本),但我们建议直接从Microsoft获取最新版本。
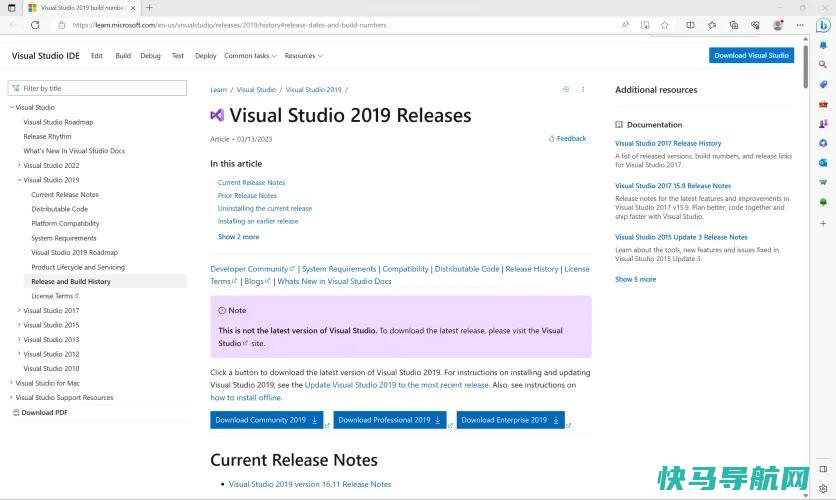
个人用户可以跳过企业版和专业版,只使用BuildTools版本的软件。
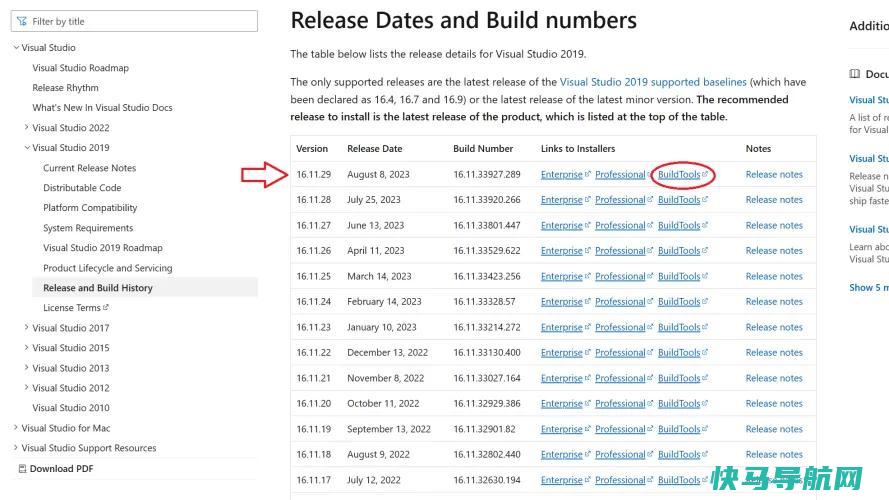
选择该选项后,确保选择“使用C++进行桌面开发”。要使其他软件正常工作,这一步骤是必不可少的。

开始下载并重新启动:根据您的互联网连接,软件可能需要几分钟才能启动。

下载Oobaboga的文本生成WebUI安装程序
接下来,您需要从Oobaboga下载文本生成WebUI工具。(是的,这是一个愚蠢的名字,但GitHub项目为人工智能提供了一个易于安装和使用的界面,所以不要被这个名字所困扰。)
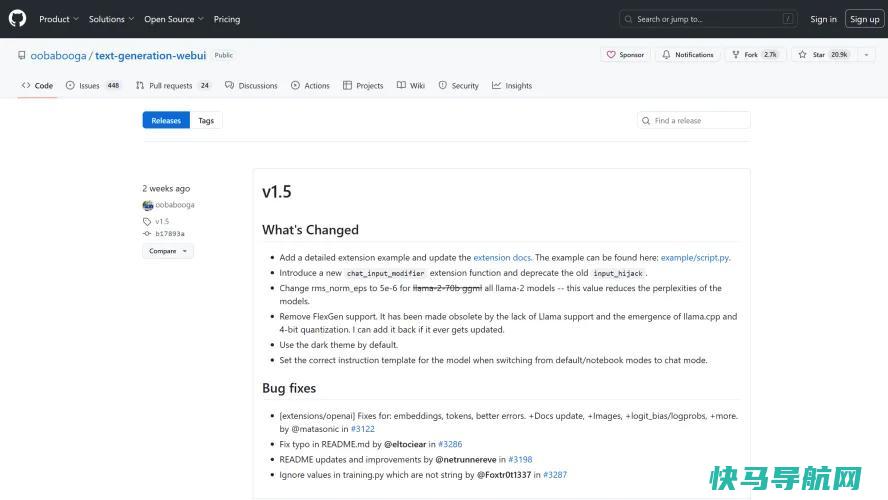
要下载该工具,你可以浏览GitHub页面,也可以直接转到Oobbooga提供的一键安装程序集合。我们已经安装了Windows版本,但您也可以在这里找到Linux和MacOS的安装程序。下载如下所示的压缩文件。

在你的电脑上某个你会记住的地方创建一个新的文件夹,并将其命名为AI_Tools或类似的名称。不要在文件夹名称中使用任何空格,因为这会扰乱安装程序的一些自动下载和安装过程。
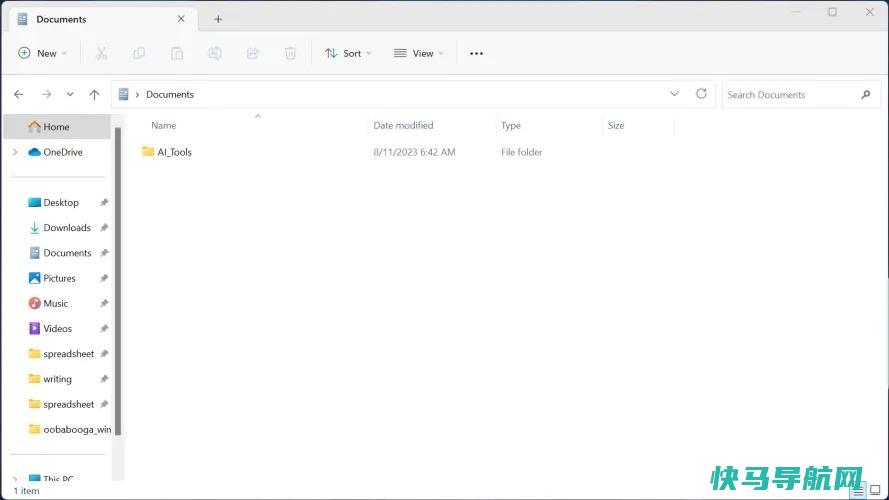
然后,将刚刚下载的压缩文件的内容解压缩到新的AI_Tools文件夹中。
运行文本生成WebUI安装程序
将压缩文件解压缩到新文件夹后,查看其中的内容。您应该会看到几个文件,包括一个名为startwindows.bat的文件。双击它以开始安装。
根据您的系统设置,您可能会收到有关Windows Defender或其他安全工具阻止此操作的警告,因为它不是由公认的软件供应商提供的。(我们没有经历或看到任何在线报告表明这些文件有任何问题,但我们重申,您这样做的风险自负。)如果要继续,请选择“更多信息”以确认是否要运行startwindows.bat。单击“仍要运行”以继续安装。
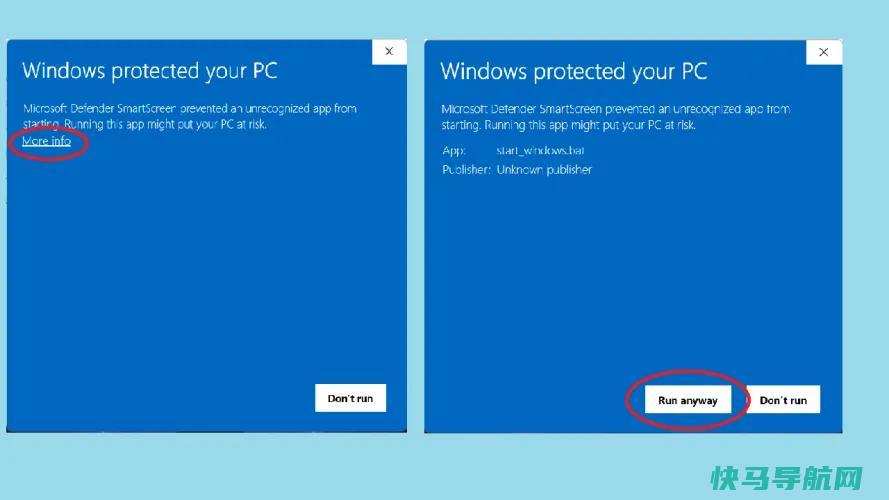
现在,安装程序将打开命令提示符(CMD)并开始安装运行文本生成WebUI工具所需的数十个软件。如果您不熟悉命令行界面,只需静观其变。

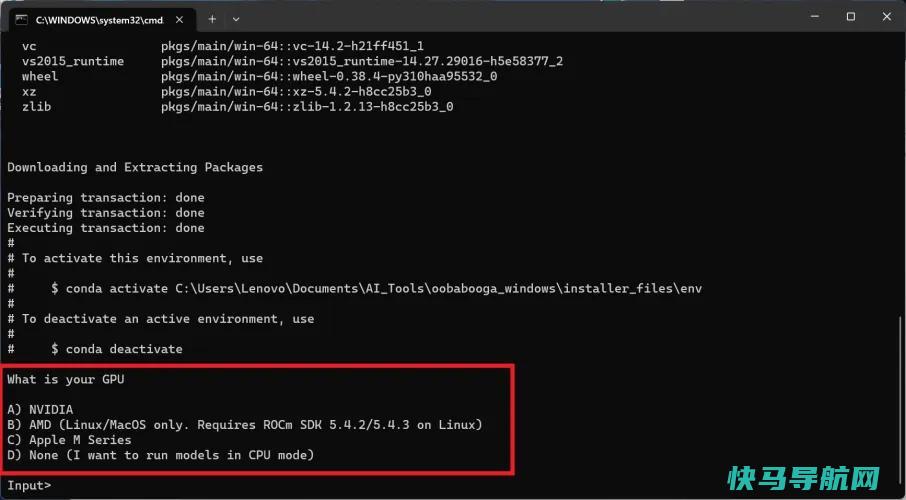
首先,你会看到许多滚动的文本,然后是由标签或英镑符号组成的简单进度条,然后会出现一个文本提示。它会问你的GPU是什么,让你有机会指出你是在使用Nvidia、AMD或Apple M系列芯片,还是只使用了一个CPU。在下载任何东西之前,你应该已经弄清楚这一点。在我们的例子中,我们选择A,因为我们的笔记本电脑配备了NVIDIA图形处理器。
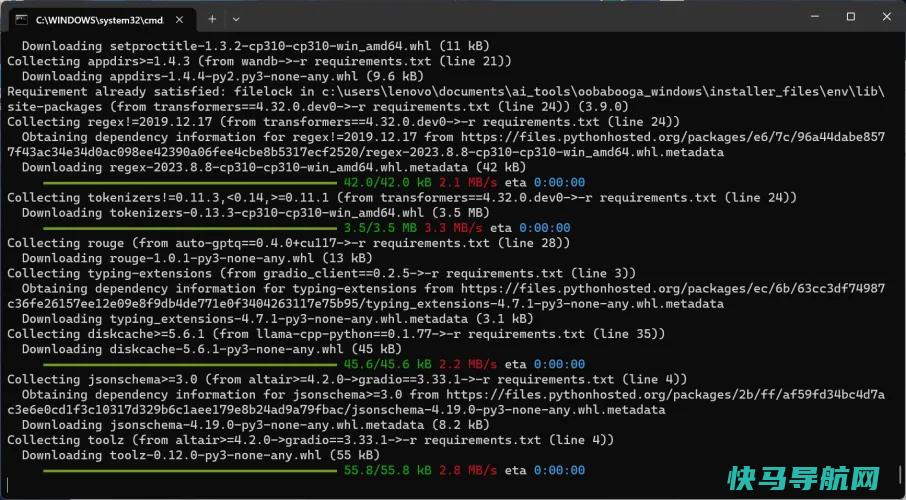
一旦你回答了问题,安装程序就会处理剩下的事情。你会看到大量的文本滚动,然后是简单的文本进度条,然后是更形象的粉色和绿色进度条,因为安装程序下载并设置了它所需的一切。
在此过程结束时(可能需要长达一个小时),您将看到一条由星号包围的警告消息。该警告将告诉您尚未下载任何大型语言模型。真是个好消息!这意味着文本生成WebUI的安装即将完成。
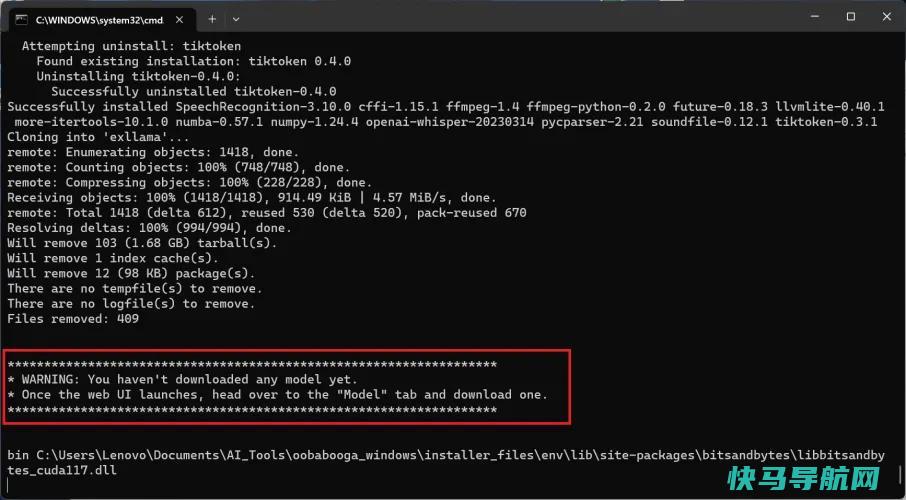
此时,您将看到一些绿色文本,上面写着“信息:正在加载扩展库”。您的安装已完成,但不要关闭命令窗口。
复制并粘贴WebUI的本地地址。
在绿色文本的正下方,您将看到另一行内容为“Running on local url:HTTP://127.0.01:7860.”只需点击URL文本,它将打开您的Web浏览器,显示文本生成WebUI-您的所有LLM界面。
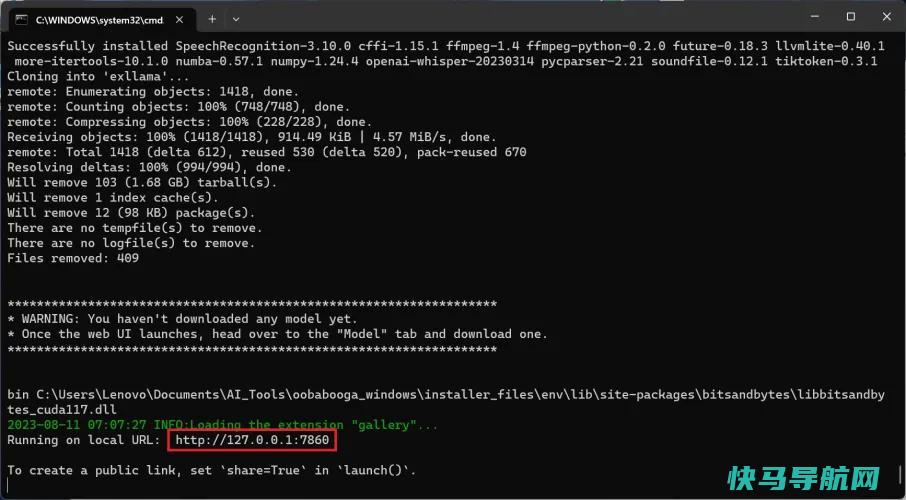
您可以将此URL保存在某个位置或在浏览器中将其添加为书签。尽管文本生成WebUI是通过浏览器访问的,但它在本地运行,因此即使您的Wi-Fi关闭,它也会运行。此Web界面中的所有内容都是本地的,生成的数据应该是您和您的计算机的私有数据。

关闭并重新打开WebUI
成功访问WebUI以确认其安装正确后,继续并关闭浏览器和命令窗口。
在您的AI_Tools文件夹中,打开我们用来安装所有东西的相同的Start_Windows批处理文件。它将重新打开CMD窗口,但不是完成整个安装过程,而是加载一些文本,包括中的绿色文本,然后告诉您扩展库已加载。这意味着WebUI已准备好在您的浏览器中再次打开。
使用之前复制或添加书签的相同本地URL,WebUI界面将再次向您致意。这就是您将来打开该工具的方式,让CMD窗口在后台打开。
选择并下载LLM
现在您已经安装并运行了WebUI,是时候找到要加载的模型了。正如我们所说的,你会发现数以千计的免费LLM可以下载并与WebUI一起使用,安装一个的过程非常简单。
如果你想要一个最推荐车型的精选列表,你可以查看一个社区,比如Reddit‘s/r/LocalLlaMA,其中包括一个社区维基页面,其中列出了几十个型号。它还包括有关构建不同型号的信息,以及有关不同硬件支持哪些型号的数据。(一些LLM专门用于编码任务,而另一些则是为自然文本聊天而构建的。)
这些清单最终都会把你送到拥抱脸,那里已经成为了LLM和资源的储存库。如果你从Reddit来到这里,你可能会被直接指向一个型号卡,这是一个关于特定可下载型号的专用信息页面。这些卡片提供一般信息(如使用的数据集和培训技术)、要下载的文件列表和社区页面,人们可以在其中留下反馈以及请求帮助和错误修复。
在每个型号卡片的顶部都有一个大的、粗体的型号名称。在我们的案例中,我们使用了Eric Hartford制造的WizardLM7B未经审查的模型。他使用了网名ehartford,所以模特的列出位置是“ehartford/WizardLM-7B-Uncensired”,就像它在模型卡片顶部列出的那样。
标题旁边是一个小复制图标。点击它,它会将格式正确的模型名称保存到您的剪贴板。
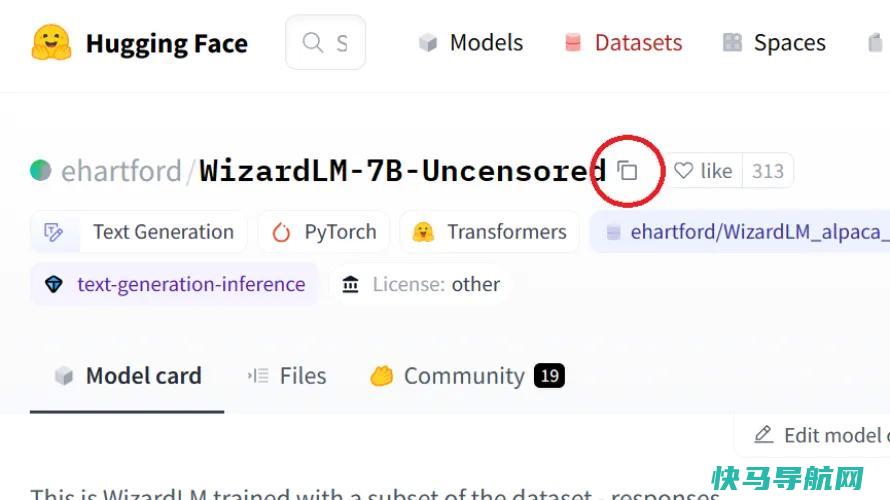
回到WebUI,转到Model选项卡,并在标记为“Download Customer Model or Lora”的字段中输入该模型名称。粘贴型号名称,点击下载,软件将开始从拥抱脸下载必要的文件。
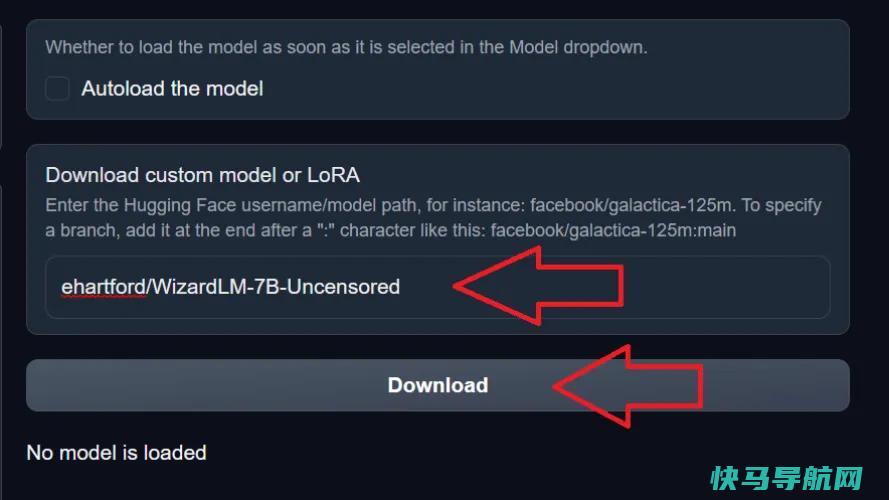
如果成功,您将在WebUI窗口中看到一个橙色的进度条弹出,并且在您在后台打开的命令窗口中将出现几个进度条。
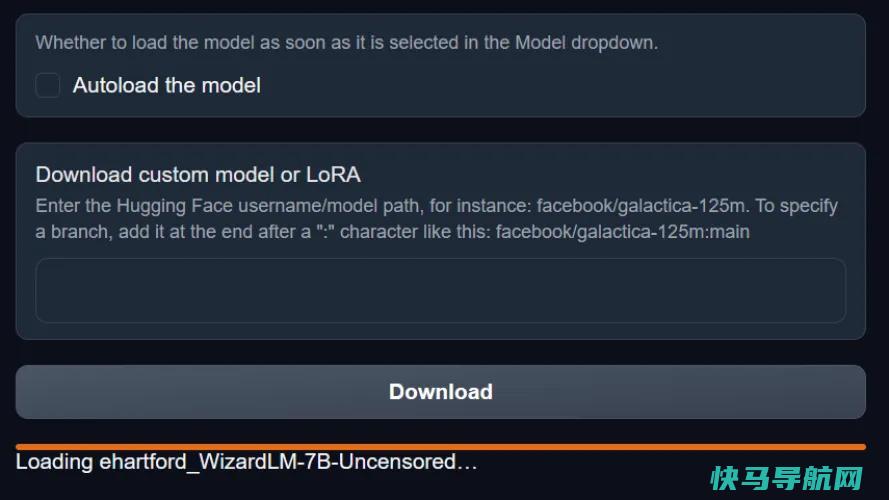
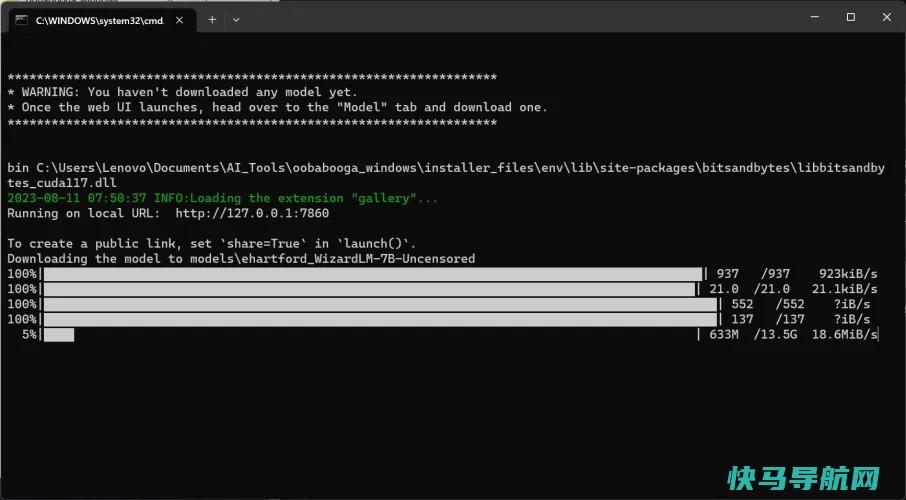
一旦完成(同样,请耐心等待),WebUI进度条将消失,它将简单地显示“完成!”取而代之的是。
在WebUI中加载模型和设置
下载模型后,需要将其加载到WebUI中。为此,请从模型选项卡左上角的下拉菜单中选择它。(如果您下载了多个型号,则需要在此处选择要使用的型号。)
在使用该模型之前,需要分配一些系统或图形内存(或两者)来运行该模型。虽然你可以在这些模型中调整和微调几乎任何你想要的东西,包括内存分配,但我发现将其设置为大约三分之二的GPU和CPU内存效果最好。这为您的其他PC功能留下了足够的未使用内存,同时仍为LLM提供了足够的内存来跟踪和保持更长的通话时间。
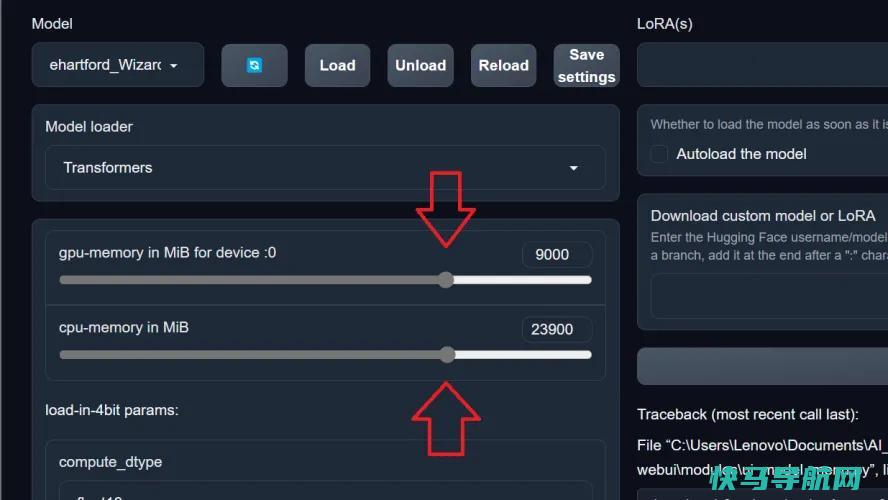
一旦您分配了内存,点击保存设置按钮保存您的选择,它将默认为该内存分配每次。如果您想更改它,只需将其重置并再次按下保存设置即可。
好好享受你的LLM吧!
你的模型装好了,准备好了,是时候开始和你的ChatGPT替代品聊天了。在WebUI中导航到文本生成选项卡。在这里,您将看到与AI聊天的实际文本界面。在框中输入文本,按Enter键发送文本,然后等待机器人响应。
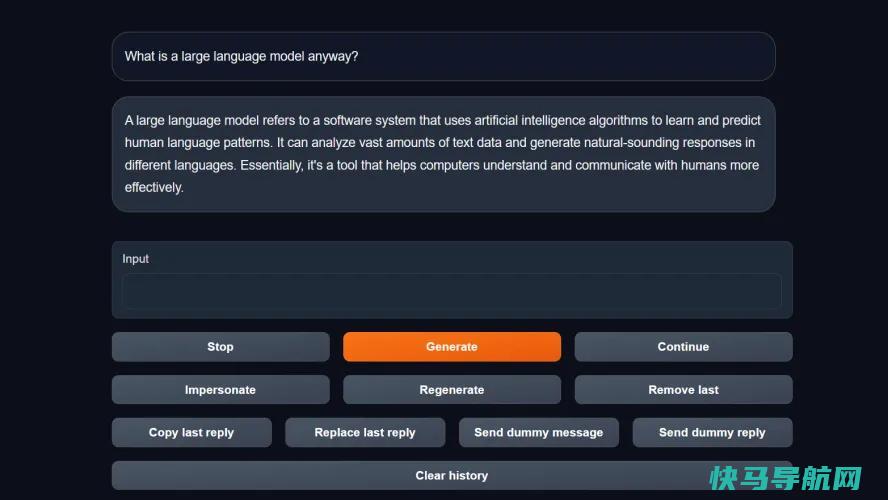
在这里,我们再说一遍,你会体验到一点失望:除非你使用的是具有多个高端GPU和海量内存的超级出色的工作站,否则你的本地LLM不会像ChatGPT或Google Bard那样快。机器人将一次吐出一个单词片段(称为令牌),每个单词之间都有明显的延迟。
然而,只要有一点耐心,你就可以与你下载的模型进行充分的对话。你可以向它询问信息,玩基于聊天的游戏,甚至给它一个或多个个性。此外,您可以使用LLM,确保您的对话和数据是隐私的,这可以让您高枕无忧。
在开始学习本地LLM时,您会遇到大量的内容和概念供您探索。随着您越来越多地使用WebUI和不同的模型,您将更多地了解它们的工作原理。如果你不知道你的文本和令牌,或者你的GPTQ和LORA,这些是开始沉浸在机器学习世界中的理想地方。
外链关键词: 山东专升本宣誓 德州康宝莱经销商地址电话 计算机水平考试成绩 沐川县舟坝中学历任校长 奥数培训班加盟 黄子韬什么星座 清华最热的专业 博世空调滤芯怎么样本文地址: https://www.q16k.com/article/d5df8177c2adec0b77e1.html

公考网为考生提供2024年国家公务员考试、2024年省公务员考试、2024年事业单位考试、人事考试、公务员考试时间、成绩查询、试题练习、题库大全、用书推荐、考试论坛、报名时间、报名入口、报考条件、职位表、考试公告、考试时间、考试科目、考试大纲、历年真题、分数线查询等公考信息。

该站点未添加描述description...

先疯-道理讲多了就像借口
沙苑影视是一个电影爱好者自制的优秀电影分享网站,有动画片、动作片、科幻片等等,所有电影免费畅看,真正实现电影自由啦!
饮茶人网,专注于为茶友分享普洱、黑茶、白茶、黄茶、红茶、绿茶、花茶、乌龙茶等各类茶叶知识常识的网站,包括茶叶冲泡方法、选购鉴别与存放、功效与作用、茶叶价格、茶树种植、喝茶养生等内容。
暮思语录提供美文摘抄和励志名言以及正能量的句子。经典美文和唯美句子以及经典说说大全,伤感日志人生感悟。欢迎关注!
该站点未添加描述description...

该站点未添加描述description...
该站点未添加描述description...
该站点未添加描述description...
使用世界前沿的人工智能技术,为用户甄选海量的高清美图,用更流畅、更快捷、更精准的搜索体验,带你去发现多彩的世界。
潜江楼市资讯为您提供2022潜江楼盘的新动态,您可以看到潜江新的楼市行情和楼市新闻,了解潜江楼市政策,帮您快速解决房产相关问题。
该站点未添加描述description...
该站点未添加描述description...
该站点未添加描述description...
")
安兔兔评测是一款专业级跑分软件,支持Vulkan、UFS3.0等最新技术,可以让您清楚了解手机的真实性能。安兔兔验机应用,则可以检验手机的真伪,获取硬件参数。安兔兔关注业界热点,实时为您更新手机资讯、新机跑分曝光、新机硬件参数、行业数据。
该站点未添加描述description...

专注为创业者提供学习交流的创业网站,提供全方位的媒体资讯,分析各类成功商业模式,让你在创业中快速找到成功的方向!

有两个机场向我推销了eSIM卡:纽瓦克自由国际机场(NewarkLibertyInternationalAirport),我在那里租了一张eSIM卡,几分钟后就用Pixel7设置好了;还有JosepTarradellas巴塞罗那-埃尔普拉特机场(JosepTarradellas巴塞罗那-ElPratAirport),在那里,我不必在倒...
ChatGPT是科技行业的最新流行语,但普通互联网用户可能不知道他们如何利用人工智能聊天机器人,因为有朝一日它可能会抢走他们的工作。乍一看,人工智能似乎只是另一项被过度炒作的技术–或许类似于NFTs和虚拟现实。然而,即使在刚刚起步的时候,人工智能聊天机器人就已经显示出自动执行不需要大脑的任务、产生想法和简化信息的潜力。谷歌在ChatG...
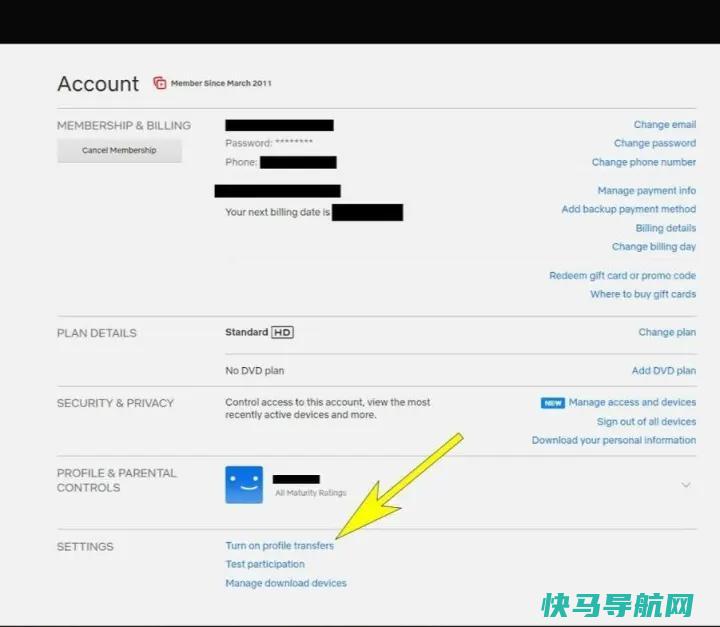
如果你正在窃取别人的Netflix账户,即将到来的密码共享打击行动可能会让你受到惊吓。这家流媒体服务公司还没有透露最终细节,但如果你想在访问被切断之前采取行动,你可以将个人资料转移到你自己的订阅中,同时仍然保留你的所有推荐、观看名单等。Netflix让这一过程变得略显困难。您不仅必须将自己的个人资料转移到新帐户,还必须确保原始帐户所有...
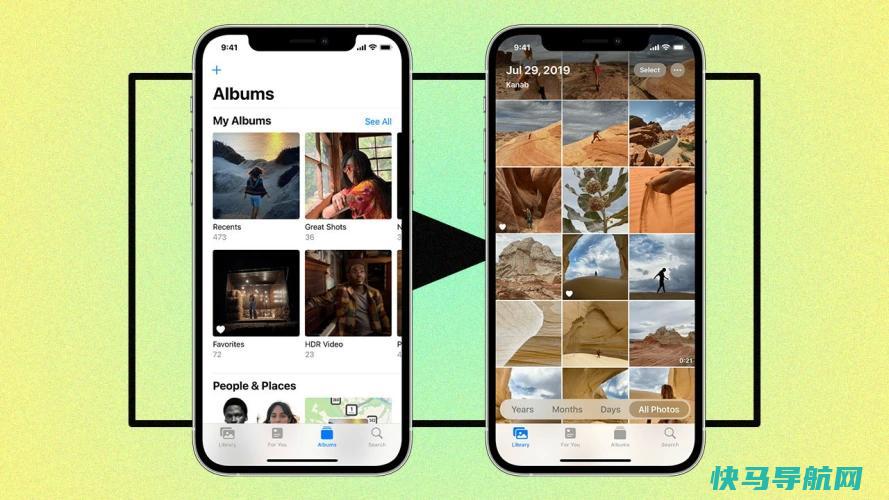
想要在你的iPhone或iPad上建立一个照片幻灯片吗?你可以直接在ApplePhotos中做到这一点。你所要做的就是从你的设备中选择镜头,添加带有字体和背景音乐的特殊主题,然后与其他人分享最终产品。Photos应用程序提供两种不同类型的幻灯片。常规幻灯片允许您根据特定数量的选定照片更改主题、音乐和持续时间。一个Memory视频可以让...

当我在90年代末和00年代初上公立学校的时候,我学会了如何执行现在已经过时的任务,比如用草书书写,平衡支票簿,以及使用杜威十进制系统。我敢肯定,我的Z世代和阿尔法世代的同胞从来没有在家政课上练习过晚餐礼仪,而且,比如说,1998年后出生的人都不知道在手工课上接触嗡嗡作响的圆锯会带来的恐惧。美国公立学校的课程几十年来一直在演变,但它需要...

如果你不能在iPhone上的ApplePhotos应用程序中做一些事情,那么有可能有第三方照片编辑应用程序可以做。例如,你有没有看过一张LivePhoto,然后意识到它会制作出更好的视频?使用快捷键应用程序完成这项工作。它只需要几分钟的时间来设置和几个轻击来执行。如何将现场照片转换为视频苹果的快捷方式应用程序应该已经安装在你的iPho...

打造自己的游戏PC–无论它是您的第一台还是您的第十台–是一项令人兴奋的冒险。对于一些人来说,创建自己的计算机,然后测试其局限性的乐趣本身就是回报。对于其他人来说,乐趣在于让系统的外观恰到好处地吹嘘自己的权利,然后是第一次开机时的兴奋。首先,在你拿起螺丝刀之前,你需要做相当多的研究,想想你到底想要一台游戏PC有什么。如果你想打造一台紧凑...

如果你已经制造了很长一段时间的PC,有些东西是如此根深蒂固,你会认为它们就是这样的。你总是需要用细小的电缆来连接前面板上的灯、开关和端口。为一大群冷却风扇连接电缆?为了让你的电脑看起来很整洁,你需要做一些花哨的手指工作。你有没有装上液体冷却器?可以保证,这将是一捆钻头、螺丝和蜿蜒的电缆,会让美杜莎脸红。海盗号不是一天就能解决这些问题的...

您的咖啡煮好了。你的头脑很敏锐。你去打开你的电脑,但什么也没有出现–你所看到的只是一个黑屏,没有解释你一天中所有珍贵的迷因藏在哪里。空白屏幕很难诊断,因为有太多因素可以导致它。您的整个计算机可能出现故障,也可能只是监视器出现故障。也许你会收到一条类似“没有输入”或“电缆没有连接”的信息,或者它什么也没说。让我们来演练一些故障排除步骤,...

多年来,微软打造的网络浏览器一直是人们的笑柄,但多亏了谷歌,Edge扭转了局面。由于它们共享相同的Chromium基础,这两个浏览器非常相似,因此切换起来非常容易。大多数基本功能是相同的,您甚至可以安装相同的扩展。然而,Edge的表现往往略好于Chrome–不仅在网络浏览基准测试中,而且在硬件使用方面。虽然Chrome因占用内存和其他...
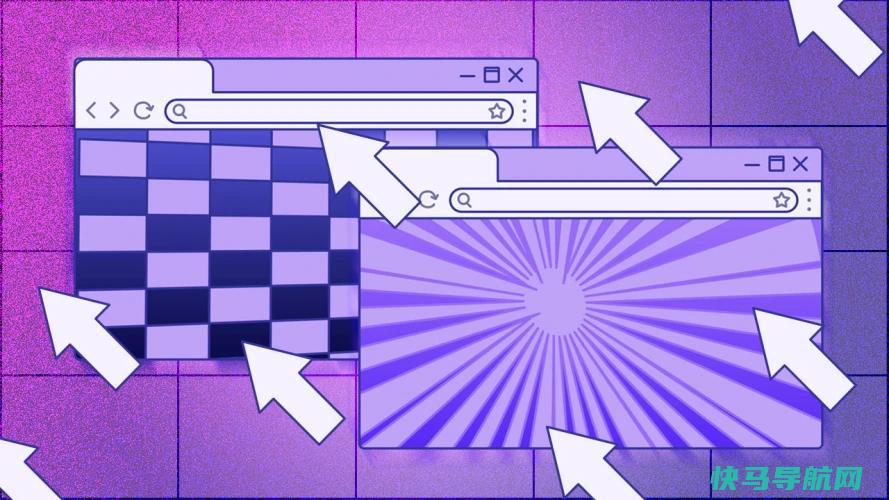
你的浏览器书签有没有变得杂乱无章?你保存的网页越多,你的书签列表就会变得越长,越难以管理,特别是如果你不能将它们放在自己的文件夹中的话。不要害怕。无论你使用Chrome、Firefox还是Edge,你都可以使用当前的书签来重新组织它们,以便更容易地访问它们。您还可以使用合适的工具在多台PC和设备上的不同浏览器之间同步书签。首先,让我们...

性工作是最古老的职业,互联网当然也是如此,在互联网上,网络色情一直是创新的推动力和魔鬼。也许在疫情最严重的时候,在线色情内容的重要性从未像现在这样明显,当时我们中的许多人都被困在家里工作和娱乐,与所有人保持至少六英尺的距离。虽然色情仍然是一种受欢迎的解脱,即使流行病正在消退,但消费色情也会危及你的隐私(至少是你的尊严)。顺便提一句:除...

如果其他人不能和你一起坐在沙发上,有很多方法可以和他们分享视频游戏。你可以在线玩多人游戏,在Twitch上流媒体游戏,或者与不和谐的朋友分享它。如果你有一台PlayStation5,还有一个名为SharePlay的额外选项,可以让你和朋友分享你的屏幕,也让他们接管游戏,这样你们就可以一起玩了。以下是如何设置该功能并一起玩。共享屏幕或共...
我们中的许多人的工作需要每天盯着屏幕超过8个小时。(另外四个小时则用来盯着智能手机、平板电脑或电视看。)所有的光线和持续的调焦/重新调焦都会给你的眼睛带来真正的压力。但由于大多数人不能就这样放弃所有的背光技术,我们转向了蓝光滤镜或眼镜等快速解决方案。另一个简单的选择是:将亮白色背景换成暗模式的灰色和黑色,让你的眼睛休息一下(并节省一些...

你是否厌倦了你接到的所有废品电话?FCC试图打击这种呼声,而联邦和州一级的立法者已经通过了立法来解决这个问题。但有一些行动你可以自己采取。安卓设备和iPhone都内置了屏蔽特定电话号码的功能,而移动运营商则提供了自己的屏蔽工具。几个第三方应用程序也可以阻止电话营销呼叫,包括Hiya、RoboKiller、Truecaller和Call...
您的咖啡煮好了。你的头脑很敏锐。你去打开你的电脑,但什么也没有出现–你所看到的只是一个黑屏,没有解释你一天中所有珍贵的迷因藏在哪里。空白屏幕很难诊断,因为有太多因素可以导致它。您的整个计算机可能出现故障,也可能只是监视器出现故障。也许你会收到一条类似“没有输入”或“电缆没有连接”的信息,或者它什么也没说。让我们来演练一些故障排除步骤,...

在电影《瞬息全宇宙》中,一位多管闲事的美国国税局特工(杰米·李·柯蒂斯饰)遇到了伊夫林,她正在旁听的是一名苦苦挣扎的洗衣店老板/多元宇宙跳跃者(杨紫琼饰)。被凌乱的商业收据和其他与税务有关的文件包围着,这位美国国税局特工解释说,伊夫林需要能够区分爱好和业务,她需要为每一家小企业制定一个时间表C。多元宇宙旅行可能比在你的所得税表格上与多...

多亏了现代技术的奇迹,你不再需要满足于你的门铃通常发出的无聊的旧铃声、叮当声和叮当声。如果你的房子配备了智能门铃,你通常只需在附带的应用程序上点击几下就可以改变它发出的声音。许多最受欢迎的款式甚至还提供现成的假日主题包,这样你就可以设置你的声音来适应季节。以下是如何让你的门铃为你的访客播放诡异的万圣节噪音:鸟巢这是一堆中最简单的。首先...

本文目录导航:安徽省安庆市桐城市大关小关用什么打车安庆可靠的找对象平台?安庆拖三在哪下载安徽省安庆市桐城市大关小关用什么打车滴滴现在有很多打车软件,现在最常用的打车软件就是滴滴打车,有些也可以用手拦出租车的,还有约网约车司机。安庆可靠的找对象平台?在安庆怎么通过网络找对象脱单呢?软件挺多的,我介绍几个比较靠谱而且杭州人用比较多的平台:...

你已经准备好打扫房子,清理车库,收拾办公室里堆积的零碎东西。这是令人钦佩的。但是你要怎么处理你不想要的东西呢?许多人知道他们应该负责任地处理不需要的物品,包括电子废品。什么是“负责任的”是让很多人猜测的部分。如果有疑问,那就把它从废品桶里扔出去。以下是你需要知道的。如何转售电脑、平板电脑和智能手机对于处于工作状态的电脑、平板电脑和智能...